字典被广泛应用于实现Redis的各种功能,其中包括数据库和哈希键。
字典,又称符号表(symbol table)、关联数组(associative array)或者映射(map
),是一种用来保存键值对(key-value pair)的抽象数据结构。
本文主要介绍如下内容:
- Redis字典的实现及特点
- Redis字典源码难点分析
- Redis字典源码部分节选
Redis字典的实现及特点
Redis的数据库就是使用字典作为底层实现的,堆数据库的增删查改操作也是构建在对字典的操作之上的。
字典还是哈希键的底层实现之一: 当一个哈希键包含的键值对比较多, 又或者键值对中的元素都是比较长的字符串时, Redis 就会使用字典作为哈希键的底层实现。
举个例子, website 是一个包含 10086 个键值对的哈希键, 这个哈希键的键都是一些数据库的名字, 而键的值就是数据库的主页网址:1
2
3
4
5
6
7
8
9
10
11HLEN website
(integer) 10086
HGETALL website
1) "Redis"
2) "Redis.io"
3) "MariaDB"
4) "MariaDB.org"
5) "MongoDB"
6) "MongoDB.org"
...
website 键的底层实现就是一个字典, 字典中包含了 10086 个键值对:
其中一个键值对的键为 “Redis” , 值为 “Redis.io”;
另一个键值对的键为 “MariaDB” , 值为 “MariaDB.org” ;
还有一个键值对的键为 “MongoDB” , 值为 “MongoDB.org” ;
诸如此类。
具体实现(数据结构)
Redis的字典使用哈希表作为底层实现,一个哈希表里面可以有多个哈希表节点,每个哈希表节点就保存了字典中的一个键值对。
哈希表节点:1
2
3
4
5
6
7
8
9
10typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
dictEntry结构中key保存着键值对中的键, 而 v 属性则保存着键值对中的值, 其中键值对的值可以是一个指针, 或是一个uint64_t 整数,或是一个 int64_t 整数,亦或是一个double类型整数。
next是指向另一个哈希表节点的指针, 这个指针可以将多个哈希值相同的键值对连接在一次, 以此来解决键冲突(collision)的问题。Redis是用链地址法(separate chaining)来解决键冲突的,可以参考解决键冲突的多种方法:哈希表——线性探測法、链地址法、查找成功、查找不成功的平均长度。
哈希表:1
2
3
4
5
6
7
8/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
dictht结构中table是一个数组,数组中的每个元素都是一个指向 dict.h/dictEntry 结构的指针, 每个dictEntry结构保存着一个键值对。
size则记录了哈希表的大小, 也即是 table 数组的大小, 而 used 属性则记录了哈希表目前已有节点(键值对)的数量。
sizemask 属性的值总是等于 size - 1 , 这个属性和哈希值一起决定一个键应该被放到 table 数组的哪个索引上面。
下图便是一个空的哈希表
字典结构如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;
字典结构图示如下: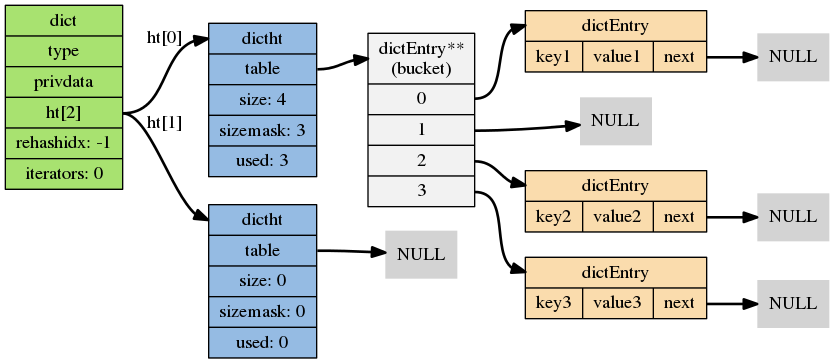
Redis字典结构中使用2个哈希表,主要是为了方便进行rehash。在没有进行rehash时,使用的是ht[0];在 rehash 进行时, 才会同时使用 0 号和 1 号哈希表。dictType主要是方便指定对于key复制函数,value复制函数,key比较函数,key释放函数,value释放函数。
Redis字典的特点
- Redis字典的底层实现为哈希表
- 每个字典使用两个哈希表, 一般情况下只使用 0 号哈希表, 只有在 rehash 进行时, 才会同时使用 0 号和 1 号哈希表
- 哈希表使用链地址法来解决键冲突的问题
- 自动 Rehash 扩展或收缩哈希表
- 对哈希表的 rehash 是分多次、渐进式地进行的(防止rehash时间太长,对上层造成阻塞)
关于rehash
本文暂不介绍rehash,有兴趣的可以参考rehash
其实这个rehash并不难理解,把相应的几个函数看明白就自然懂了: )1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53/* Performs N steps of incremental rehashing. Returns 1 if there are still
* keys to move from the old to the new hash table, otherwise 0 is returned.
*
* Note that a rehashing step consists in moving a bucket (that may have more
* than one key as we use chaining) from the old to the new hash table, however
* since part of the hash table may be composed of empty spaces, it is not
* guaranteed that this function will rehash even a single bucket, since it
* will visit at max N*10 empty buckets in total, otherwise the amount of
* work it does would be unbound and the function may block for a long time. */
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
unsigned int h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
Redis字典源码难点分析
难点一:typedef用法
可能有的同学对如下typedef用法较为陌生1
typedef void (dictScanFunction)(void *privdata, const dictEntry *de);
理解typedef void (dictScanFunction)(void privdata, const dictEntry de);的表达。这里定义的不是函数指针,而是一种函数类型,可以利用 dictScanFunction完成类似函数指针的用法,看下面的例子(基础概念–typedef的学习 ):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
using namespace std;
void PrintWord(int n) {
cout << n << endl;
}
int main() {
//1
typedef void (func1)(int);//不是函数指针,定义了一个函数类型
func1 *myfunc1;//定义函数指针
myfunc1 = PrintWord;
myfunc1(5);
//2
typedef void(*func2)(int);//定义了一种类型,2和3的区别在于typedef的作用上
func2 myfunc2;//实例化
myfunc2 = PrintWord;
myfunc2(5);
//3
void(*func3)(int);
func3 = PrintWord;
func3(5);
while (1);
return 0;
}
难点二:关于翻转整数的二进制
代码如下:1
2
3
4
5
6
7
8
9
10
11/* Function to reverse bits. Algorithm from:
* http://graphics.stanford.edu/~seander/bithacks.html#ReverseParallel */
static unsigned long rev(unsigned long v) {
unsigned long s = 8 * sizeof(v); // bit size; must be power of 2
unsigned long mask = ~0;
while ((s >>= 1) > 0) {
mask ^= (mask << s);
v = ((v >> s) & mask) | ((v << s) & ~mask);
}
return v;
}
解析:上述代码完成了对无符号long整型数v的二进制位的翻转。比如原来是0x0011(3),翻转之后就是0x1100(12)。在32bit的平台上,sizeof(unsigned long)是等于4的,也就是上述的s等于8*4=32;s右移一位,相当于s/=2,也就是第一次s=16;每次mask计算得到的值分别是:0x0000ffff、0x00ff00ff、0x0f0f0f0f、0x33333333和0x55555555。经过以上几次位相关的运算,便可得到按二进制位翻转之后的数,详细可以参考翻转整数的二进制位。
难点三 其中的扫描函数dictScan
扫描函数源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154/* dictScan() is used to iterate over the elements of a dictionary.
*
* Iterating works the following way:
*
* 1) Initially you call the function using a cursor (v) value of 0.
* 2) The function performs one step of the iteration, and returns the
* new cursor value you must use in the next call.
* 3) When the returned cursor is 0, the iteration is complete.
*
* The function guarantees all elements present in the
* dictionary get returned between the start and end of the iteration.
* However it is possible some elements get returned multiple times.
*
* For every element returned, the callback argument 'fn' is
* called with 'privdata' as first argument and the dictionary entry
* 'de' as second argument.
*
* HOW IT WORKS.
*
* The iteration algorithm was designed by Pieter Noordhuis.
* The main idea is to increment a cursor starting from the higher order
* bits. That is, instead of incrementing the cursor normally, the bits
* of the cursor are reversed, then the cursor is incremented, and finally
* the bits are reversed again.
*
* This strategy is needed because the hash table may be resized between
* iteration calls.
*
* dict.c hash tables are always power of two in size, and they
* use chaining, so the position of an element in a given table is given
* by computing the bitwise AND between Hash(key) and SIZE-1
* (where SIZE-1 is always the mask that is equivalent to taking the rest
* of the division between the Hash of the key and SIZE).
*
* For example if the current hash table size is 16, the mask is
* (in binary) 1111. The position of a key in the hash table will always be
* the last four bits of the hash output, and so forth.
*
* WHAT HAPPENS IF THE TABLE CHANGES IN SIZE?
*
* If the hash table grows, elements can go anywhere in one multiple of
* the old bucket: for example let's say we already iterated with
* a 4 bit cursor 1100 (the mask is 1111 because hash table size = 16).
*
* If the hash table will be resized to 64 elements, then the new mask will
* be 111111. The new buckets you obtain by substituting in ??1100
* with either 0 or 1 can be targeted only by keys we already visited
* when scanning the bucket 1100 in the smaller hash table.
*
* By iterating the higher bits first, because of the inverted counter, the
* cursor does not need to restart if the table size gets bigger. It will
* continue iterating using cursors without '1100' at the end, and also
* without any other combination of the final 4 bits already explored.
*
* Similarly when the table size shrinks over time, for example going from
* 16 to 8, if a combination of the lower three bits (the mask for size 8
* is 111) were already completely explored, it would not be visited again
* because we are sure we tried, for example, both 0111 and 1111 (all the
* variations of the higher bit) so we don't need to test it again.
*
* WAIT... YOU HAVE *TWO* TABLES DURING REHASHING!
*
* Yes, this is true, but we always iterate the smaller table first, then
* we test all the expansions of the current cursor into the larger
* table. For example if the current cursor is 101 and we also have a
* larger table of size 16, we also test (0)101 and (1)101 inside the larger
* table. This reduces the problem back to having only one table, where
* the larger one, if it exists, is just an expansion of the smaller one.
*
* LIMITATIONS
*
* This iterator is completely stateless, and this is a huge advantage,
* including no additional memory used.
*
* The disadvantages resulting from this design are:
*
* 1) It is possible we return elements more than once. However this is usually
* easy to deal with in the application level.
* 2) The iterator must return multiple elements per call, as it needs to always
* return all the keys chained in a given bucket, and all the expansions, so
* we are sure we don't miss keys moving during rehashing.
* 3) The reverse cursor is somewhat hard to understand at first, but this
* comment is supposed to help.
*/
unsigned long dictScan(dict *d,
unsigned long v,
dictScanFunction *fn,
void *privdata)
{
dictht *t0, *t1;
const dictEntry *de;
unsigned long m0, m1;
if (dictSize(d) == 0) return 0;
if (!dictIsRehashing(d)) {
t0 = &(d->ht[0]);
m0 = t0->sizemask;
/* Emit entries at cursor */
de = t0->table[v & m0];
while (de) {
fn(privdata, de);
de = de->next;
}
} else {
t0 = &d->ht[0];
t1 = &d->ht[1];
/* Make sure t0 is the smaller and t1 is the bigger table */
if (t0->size > t1->size) {
t0 = &d->ht[1];
t1 = &d->ht[0];
}
m0 = t0->sizemask;
m1 = t1->sizemask;
/* Emit entries at cursor */
de = t0->table[v & m0];
while (de) {
fn(privdata, de);
de = de->next;
}
/* Iterate over indices in larger table that are the expansion
* of the index pointed to by the cursor in the smaller table */
do {
/* Emit entries at cursor */
de = t1->table[v & m1];
while (de) {
fn(privdata, de);
de = de->next;
}
/* Increment bits not covered by the smaller mask */
v = (((v | m0) + 1) & ~m0) | (v & m0);
/* Continue while bits covered by mask difference is non-zero */
} while (v & (m0 ^ m1));
}
/* Set unmasked bits so incrementing the reversed cursor
* operates on the masked bits of the smaller table */
v |= ~m0;
/* Increment the reverse cursor */
v = rev(v);
v++;
v = rev(v);
return v;
}
字典数据结构中最难理解的个人觉得就是这个函数了,看原作者给了那么长的注释,也可以看出作者希望读者通过注释能理解这段代码。这段代码主要功能就是就是根据给定的游标v,用给定的扫描函数,扫描相应哈希表中t0->table[v & m0]这个bucket中的各个dictEntry;然后根据特定的算法返回一个游标v,注意该函数并没有按我们常规的想法,就是把v++,之所以没有这样做,是因为字典可能存在rehash的过程,这使字典可能扩展,也可能缩小。然而扫描迭代的时候又希望不漏掉遍历开始那一刻的所有元素,又希望把返回重复元素的可能性降到最低,因此便有了上述的很巧妙的算法。
我们看下扫描函数中关于游标v的关键部分:1
2
3
4
5
6
7
8v |= ~m0;
/* Increment the reverse cursor */
v = rev(v);
v++;
v = rev(v);
return v;
在Redis的字典中哈希表的长度始终是2的n次方,m0也就始终是2^n -1,比如长度为8时,m0=0x111;
所以第一步:v |= ~m0;就只保留了v的低n位,其余位全置1;
第二步:v = rev(v);将v的二进制位进行翻转,所以v的低n位变成了高n位
第三步:v++;这个时候其实最右边是1,+1是向正常的高位进位
第四步:v = rev(v);再翻转回来。
因此这四步总结起来就是:向最高位加1,且向低位方向进位。
比如:
当长度为8时,游标cursor的变化过程就是这样:1
000 --> 100 --> 010 --> 110 --> 001 --> 101 --> 011 --> 111 --> 000
关于这部分可以参考Redis源码解析:04字典的遍历dictScan。
理解这个过程,那么该dictScan函数就好理解了,主要就是针对有没有在做rehash,如果没有在做rehash,这种情况比较简单,直接在d->ht[0]这个哈希表中根据v找到需要迭代的bucket索引,针对该bucket中链表中的所有节点,调用用户提供的fn函数即可。
对于正在rehash的情况,需要先遍历较小的哈希表,然后遍历较大的哈希表。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15/* Iterate over indices in larger table that are the expansion
* of the index pointed to by the cursor in the smaller table */
do {
/* Emit entries at cursor */
de = t1->table[v & m1];
while (de) {
fn(privdata, de);
de = de->next;
}
/* Increment bits not covered by the smaller mask */
v = (((v | m0) + 1) & ~m0) | (v & m0);
/* Continue while bits covered by mask difference is non-zero */
} while (v & (m0 ^ m1));
这段代码是在遍历较大的哈希表,其中v = (((v | m0) + 1) & ~m0) | (v & m0);这是在对m0没有覆盖到的位进行加1操作,举个例子就明白了:若t0长度为8,则m0为111,若t1位16,那么m1就是1111,此时m0没有覆盖到位,就是0111的高位那个0,加1后就成了1111,其实对于111这种情况,在大的哈希表中就需要遍历0111和1111这两个bucket。
Redis字典源码部分节选
头文件dict.h源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
/* Unused arguments generate annoying warnings... */
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;
/* If safe is set to 1 this is a safe iterator, that means, you can call
* dictAdd, dictFind, and other functions against the dictionary even while
* iterating. Otherwise it is a non safe iterator, and only dictNext()
* should be called while iterating. */
typedef struct dictIterator {
dict *d;
long index;
int table, safe;
dictEntry *entry, *nextEntry;
/* unsafe iterator fingerprint for misuse detection. */
long long fingerprint;
} dictIterator;
typedef void (dictScanFunction)(void *privdata, const dictEntry *de);
/* This is the initial size of every hash table */
/* ------------------------------- Macros ------------------------------------*/
/* API */
dict *dictCreate(dictType *type, void *privDataPtr);
int dictExpand(dict *d, unsigned long size);
int dictAdd(dict *d, void *key, void *val);
dictEntry *dictAddRaw(dict *d, void *key);
int dictReplace(dict *d, void *key, void *val);
dictEntry *dictReplaceRaw(dict *d, void *key);
int dictDelete(dict *d, const void *key);
int dictDeleteNoFree(dict *d, const void *key);
void dictRelease(dict *d);
dictEntry * dictFind(dict *d, const void *key);
void *dictFetchValue(dict *d, const void *key);
int dictResize(dict *d);
dictIterator *dictGetIterator(dict *d);
dictIterator *dictGetSafeIterator(dict *d);
dictEntry *dictNext(dictIterator *iter);
void dictReleaseIterator(dictIterator *iter);
dictEntry *dictGetRandomKey(dict *d);
unsigned int dictGetSomeKeys(dict *d, dictEntry **des, unsigned int count);
void dictPrintStats(dict *d);
unsigned int dictGenHashFunction(const void *key, int len);
unsigned int dictGenCaseHashFunction(const unsigned char *buf, int len);
void dictEmpty(dict *d, void(callback)(void*));
void dictEnableResize(void);
void dictDisableResize(void);
int dictRehash(dict *d, int n);
int dictRehashMilliseconds(dict *d, int ms);
void dictSetHashFunctionSeed(unsigned int initval);
unsigned int dictGetHashFunctionSeed(void);
unsigned long dictScan(dict *d, unsigned long v, dictScanFunction *fn, void *privdata);
/* Hash table types */
extern dictType dictTypeHeapStringCopyKey;
extern dictType dictTypeHeapStrings;
extern dictType dictTypeHeapStringCopyKeyValue;
字典添加元素:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149/* Our hash table capability is a power of two */
static unsigned long _dictNextPower(unsigned long size)
{
unsigned long i = DICT_HT_INITIAL_SIZE;
if (size >= LONG_MAX) return LONG_MAX;
while(1) {
if (i >= size)
return i;
i *= 2;
}
}
/* Expand or create the hash table */
int dictExpand(dict *d, unsigned long size)
{
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size);
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
/* Rehashing to the same table size is not useful. */
if (realsize == d->ht[0].size) return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
/* Expand the hash table if needed */
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
/* Returns the index of a free slot that can be populated with
* a hash entry for the given 'key'.
* If the key already exists, -1 is returned.
*
* Note that if we are in the process of rehashing the hash table, the
* index is always returned in the context of the second (new) hash table. */
static int _dictKeyIndex(dict *d, const void *key)
{
unsigned int h, idx, table;
dictEntry *he;
/* Expand the hash table if needed */
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
/* Compute the key hash value */
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
/* Search if this slot does not already contain the given key */
he = d->ht[table].table[idx];
while(he) {
if (dictCompareKeys(d, key, he->key))
return -1;
he = he->next;
}
if (!dictIsRehashing(d)) break;
}
return idx;
}
/* Low level add. This function adds the entry but instead of setting
* a value returns the dictEntry structure to the user, that will make
* sure to fill the value field as he wishes.
*
* This function is also directly exposed to the user API to be called
* mainly in order to store non-pointers inside the hash value, example:
*
* entry = dictAddRaw(dict,mykey);
* if (entry != NULL) dictSetSignedIntegerVal(entry,1000);
*
* Return values:
*
* If key already exists NULL is returned.
* If key was added, the hash entry is returned to be manipulated by the caller.
*/
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d);
/* Get the index of the new element, or -1 if
* the element already exists. */
if ((index = _dictKeyIndex(d, key)) == -1)
return NULL;
/* Allocate the memory and store the new entry */
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}
/* Add an element to the target hash table */
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key);
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val);
return DICT_OK;
}
该过程图示如下: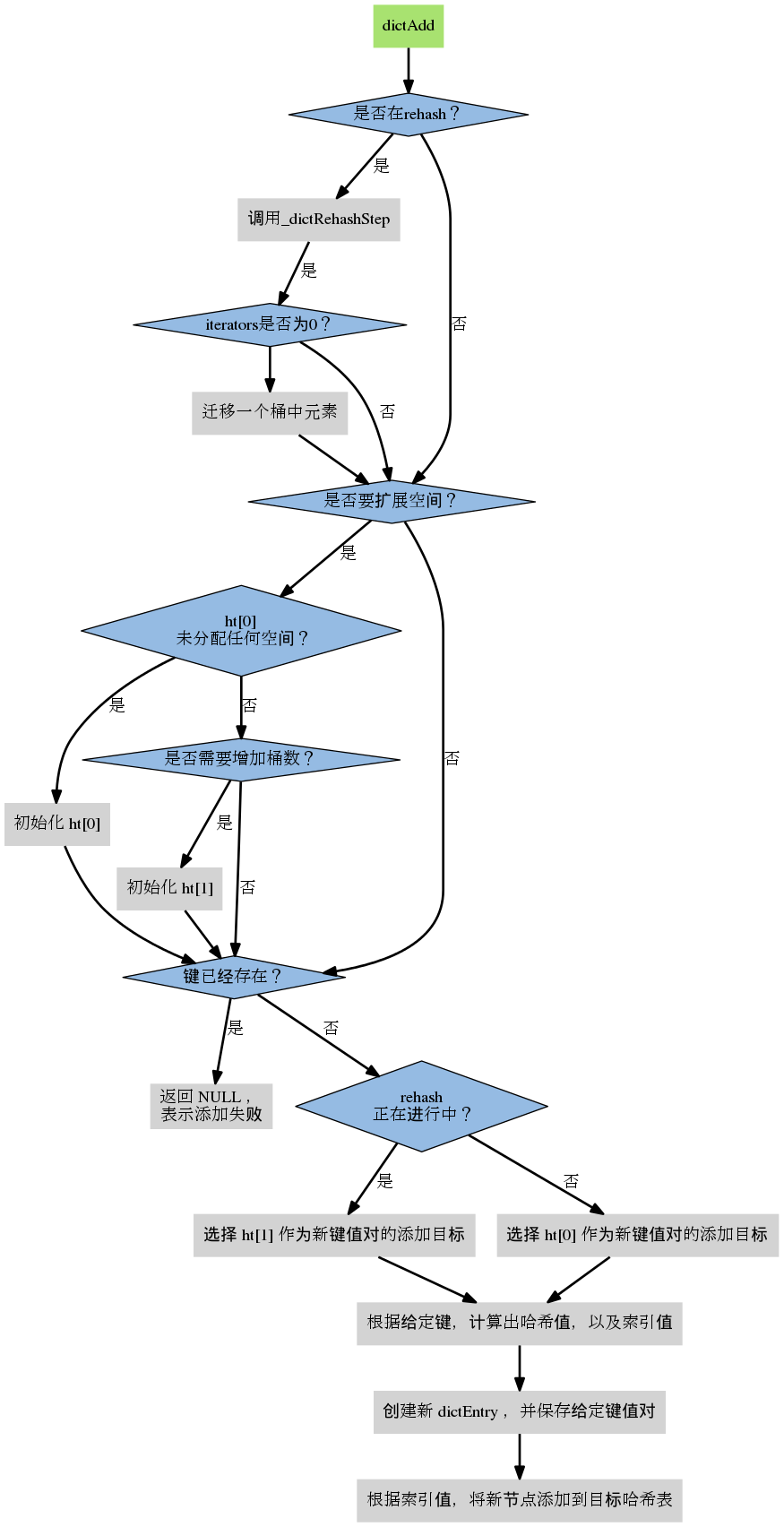
参考资料
Redis设计与实现
Redis源码3.0.6
哈希表——线性探測法、链地址法、查找成功、查找不成功的平均长度
基础概念–typedef的学习
Redis源码解析:04字典的遍历dictScan

