
本文主要介绍leveldb的Log Reader。主要就是介绍读日志的流程。
名词说明
- Slice:slice除了是levelDB上的slice,另外一层含义是一个完整的字符串,也就是一条完整的用户数据。比如用户输出一个78KB长度的字符串需要存入levelDB。这个slice在代码里面也可能叫做逻辑record
- PhysicalRecord: 可以理解为一个32K的Block,所以代码中ReadPhysicalRecord()其实就是每次读32K的Block
Log Reader流程概述
要理解这部分的代码,其实需要掌握LOG文件的物理布局。在理解物理布局的基础上来看代码就好理解了。
首先,要知道日志读取的时候就是一个Block一个Block的读的,也就是每次读32K,也就是代码中的ReadPhysicalRecord()
其实整个读日志流程,简单的来说,就是要把一条完整的数据读出来,但LOG文件的物理布局是32K大小的Block,由于单个Block可能无法存一条完整的数据,所以又添加了header来进行记录,里面会有字段标识当前block所包含的数据是不是一条完整的数据,如果不是一条完整的数据,则需要继续读,并读到的数据拼到一块,直至读到结尾标识。
下面,再回顾下LOG物理布局以帮助理解整个Log Reader流程代码。
LOG文件的物理布局就是由连续的 32K 大小 Block 构成的。
物理布局如下图:
header的结构如下: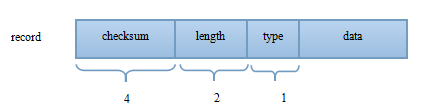
类型存在4种,可以用于判断一条数据是否完整并根据类型就拼接:
kFullType : 顾名思义记录完全在一个block中
kFirstType : 当前block容纳不下所有的内容,记录的第一片在本block中
kMiddleType : 记录的内容的起始位置不在本block,结束未知也不在本block
kLastType : 记录的内容起始位置不在本block,但 结束位置在本block
代码注释
这里列出log_reader.cc的代码注释1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
namespace leveldb {
namespace log {
Reader::Reporter::~Reporter() = default;
Reader::Reader(SequentialFile* file, Reporter* reporter, bool checksum,
uint64_t initial_offset)
: file_(file),
reporter_(reporter),
checksum_(checksum),
backing_store_(new char[kBlockSize]),
buffer_(),
eof_(false),
last_record_offset_(0),
end_of_buffer_offset_(0),
initial_offset_(initial_offset),
resyncing_(initial_offset > 0) {}
Reader::~Reader() { delete[] backing_store_; }
bool Reader::SkipToInitialBlock() {
// 在某个block中的偏移
const size_t offset_in_block = initial_offset_ % kBlockSize;
// 需要跳过的块的位置
// 这个变量的意思是说,后面在读的时候,要读的块的开头地址是什么?
uint64_t block_start_location = initial_offset_ - offset_in_block;
// Don't search a block if we'd be in the trailer
// 如果给定的初始位置的块中偏移
// 刚好掉在了尾巴上的6个bytes以内。那么
// 这个时候,应该是需要直接切入到下一个block的。
if (offset_in_block > kBlockSize - 6) {
block_start_location += kBlockSize;
}
end_of_buffer_offset_ = block_start_location;
// Skip to start of first block that can contain the initial record
if (block_start_location > 0) {
Status skip_status = file_->Skip(block_start_location);
if (!skip_status.ok()) {
ReportDrop(block_start_location, skip_status);
return false;
}
}
return true;
}
bool Reader::ReadRecord(Slice* record, std::string* scratch) {
if (last_record_offset_ < initial_offset_) {
if (!SkipToInitialBlock()) {
return false;
}
}
scratch->clear();
record->clear();
// 用于标记是不是 读在中间的状态。
bool in_fragmented_record = false;
// Record offset of the logical record that we're reading
// 0 is a dummy value to make compilers happy
uint64_t prospective_record_offset = 0;
Slice fragment;
while (true) {
// 这里是读一个物理block上的record。并不是一个完整的slice信息。
const unsigned int record_type = ReadPhysicalRecord(&fragment);
// ReadPhysicalRecord may have only had an empty trailer remaining in its
// internal buffer. Calculate the offset of the next physical record now
// that it has returned, properly accounting for its header size.
uint64_t physical_record_offset =
end_of_buffer_offset_ - buffer_.size() - kHeaderSize - fragment.size();
// resyncing_主要是指需要跳过的部分。
// 跳过的时候是跳过一个完整的record.
// 这主要是用于处理一上来就读到某条数据(Slice)中间部分的情况
// 这种情况这整条数据肯定都要跳过
if (resyncing_) {
if (record_type == kMiddleType) {
continue;
} else if (record_type == kLastType) {
resyncing_ = false;
continue;
} else {
resyncing_ = false;
}
}
// 到这里的时候,读取的就是一个完整的slice的开头了。
// 所以这里才开始正常的处理。
// 就是根据从一个物理Block读到类型进行处理
// 主要是根据类型判断是不是可以拼出完整的一条数据
// 或者本身就是一条完整的数据(kFullType的情况)
switch (record_type) {
case kFullType:
if (in_fragmented_record) {
// 既然这条数据是完整的,然而状态表示是读到数据的中间,这肯定是出错了
// Handle bug in earlier versions of log::Writer where
// it could emit an empty kFirstType record at the tail end
// of a block followed by a kFullType or kFirstType record
// at the beginning of the next block.
if (!scratch->empty()) {
ReportCorruption(scratch->size(), "partial record without end(1)");
}
}
prospective_record_offset = physical_record_offset;
scratch->clear();
*record = fragment;
last_record_offset_ = prospective_record_offset;
return true;
case kFirstType:
if (in_fragmented_record) {
// Handle bug in earlier versions of log::Writer where
// it could emit an empty kFirstType record at the tail end
// of a block followed by a kFullType or kFirstType record
// at the beginning of the next block.
if (!scratch->empty()) {
ReportCorruption(scratch->size(), "partial record without end(2)");
}
}
prospective_record_offset = physical_record_offset;
scratch->assign(fragment.data(), fragment.size());
in_fragmented_record = true;
break;
case kMiddleType:
if (!in_fragmented_record) {
// 当遇到middle type的时候。必然是“读在中间”状态。如果不是,报错!!
ReportCorruption(fragment.size(),
"missing start of fragmented record(1)");
} else {
scratch->append(fragment.data(), fragment.size());
}
break;
case kLastType:
if (!in_fragmented_record) {
// 读到lastType的时候,也必然是处在“读在中间”的状态。如果不是,报错!!
ReportCorruption(fragment.size(),
"missing start of fragmented record(2)");
} else {
scratch->append(fragment.data(), fragment.size());
*record = Slice(*scratch);
last_record_offset_ = prospective_record_offset;
return true;
}
break;
case kEof:
if (in_fragmented_record) {
// This can be caused by the writer dying immediately after
// writing a physical record but before completing the next; don't
// treat it as a corruption, just ignore the entire logical record.
scratch->clear();
}
return false;
case kBadRecord:
if (in_fragmented_record) {
ReportCorruption(scratch->size(), "error in middle of record");
in_fragmented_record = false;
scratch->clear();
}
break;
default: {
char buf[40];
snprintf(buf, sizeof(buf), "unknown record type %u", record_type);
ReportCorruption(
(fragment.size() + (in_fragmented_record ? scratch->size() : 0)),
buf);
in_fragmented_record = false;
scratch->clear();
break;
}
}
}
return false;
}
uint64_t Reader::LastRecordOffset() { return last_record_offset_; }
void Reader::ReportCorruption(uint64_t bytes, const char* reason) {
ReportDrop(bytes, Status::Corruption(reason));
}
void Reader::ReportDrop(uint64_t bytes, const Status& reason) {
if (reporter_ != nullptr &&
end_of_buffer_offset_ - buffer_.size() - bytes >= initial_offset_) {
reporter_->Corruption(static_cast<size_t>(bytes), reason);
}
}
//该函数的作用是从一个32K的block中读出一个record
//读出的record存放于result这个Slice中
//返回值则是Record的类型,以方便调用程序根据类型做相应处理
unsigned int Reader::ReadPhysicalRecord(Slice* result) {
while (true) {
//程序刚开始进来,因为这里buffer_.size() 为0,肯定是满足条件
//并且也没有到文件结尾,也就是 !eof_ 条件成立
//那么此时只需要读入一个32K的block即可
if (buffer_.size() < kHeaderSize) {
if (!eof_) {
// Last read was a full read, so this is a trailer to skip
buffer_.clear();
Status status = file_->Read(kBlockSize, &buffer_, backing_store_);
end_of_buffer_offset_ += buffer_.size();
//读入发生错误,进行报告,将eof_置为true,然后返回
if (!status.ok()) {
buffer_.clear();
ReportDrop(kBlockSize, status);
eof_ = true;
return kEof;
//读到buffer_.size() < kBlockSize,将eof_置为true后,继续循环
//其实会走到下面的else分支
} else if (buffer_.size() < kBlockSize) {
eof_ = true;
}
continue;
//eof_为true,说明读一个Record已经结束
} else {
// 注意:如果buffer_是非空的。我们有一个truncated header在文件的尾巴。
// 这可能是由于在写header时crash导致的。
// 与其把这个失败的写入当成错误来处理,还不如直接当成EOF呢。
// Note that if buffer_ is non-empty, we have a truncated header at the
// end of the file, which can be caused by the writer crashing in the
// middle of writing the header. Instead of considering this an error,
// just report EOF.
buffer_.clear();
return kEof;
}
}
// Parse the header开始分析header
//其实上面正常读完一个block后,由于不满足buffer_.size() < kHeaderSize
//程序就会运行到此处,开始处理读到一条Record
const char* header = buffer_.data();
//这提到过了,leveldb采用的是小端模式
const uint32_t a = static_cast<uint32_t>(header[4]) & 0xff;
const uint32_t b = static_cast<uint32_t>(header[5]) & 0xff;
const unsigned int type = header[6];
const uint32_t length = a | (b << 8);
//如果发生kHeaderSize + length > buffer_.size(),当然是出错了
//因为出现了头部记录的数据长度比实际的buffer_.size还要大,那肯定是出错了
if (kHeaderSize + length > buffer_.size()) {
size_t drop_size = buffer_.size();
buffer_.clear();
if (!eof_) {
ReportCorruption(drop_size, "bad record length");
return kBadRecord;
}
// If the end of the file has been reached without reading |length| bytes
// of payload, assume the writer died in the middle of writing the record.
// Don't report a corruption.
return kEof;
}
// 如果是zero type。那么返回Bad Record
// 这种情况是有可能的。比如写入record到block里面之后。可能会遇到
// 还余下7个bytes的情况。这个时候只能写入一个空的record。
if (type == kZeroType && length == 0) {
// Skip zero length record without reporting any drops since
// such records are produced by the mmap based writing code in
// env_posix.cc that preallocates file regions.
buffer_.clear();
return kBadRecord;
}
// Check crc
if (checksum_) {
uint32_t expected_crc = crc32c::Unmask(DecodeFixed32(header));
uint32_t actual_crc = crc32c::Value(header + 6, 1 + length);
if (actual_crc != expected_crc) {
// Drop the rest of the buffer since "length" itself may have
// been corrupted and if we trust it, we could find some
// fragment of a real log record that just happens to look
// like a valid log record.
size_t drop_size = buffer_.size();
buffer_.clear();
ReportCorruption(drop_size, "checksum mismatch");
return kBadRecord;
}
}
//移除已经读到的Record
//一个record可能没有占满整个32K的block,而读一次是读32K
buffer_.remove_prefix(kHeaderSize + length);
// Skip physical record that started before initial_offset_
// end_of_buffer_offset_ - buffer_.size() - kHeaderSize - length
// 这里得到的就是刚读出来的record的起始位置
// 这里可能比较难理解,其实就按默认的来,把initial_offset_换成0就理解了
if (end_of_buffer_offset_ - buffer_.size() - kHeaderSize - length <
initial_offset_) {
result->clear();
return kBadRecord;
}
*result = Slice(header + kHeaderSize, length);
return type;
}
}
} // namespace log
} // namespace leveldb
彩色版本如下(温馨提示,可能需要放大才能看清):

