本文主要介绍存储快照的使用场景、存储快照实现原理,LevelDB中的快照(snapshot),最后简单介绍快照与备份的区别。
在正式介绍LevelDB的快照之前,我们先看看通常情况下存储系统中,快照的定义。
快照的定义
简单的来说,快照是数据存储某一时刻的状态记录。
存储网络行业协会SNIA(StorageNetworking Industry Association)快照的定义则是:关于指定数据集合的一个完全可用拷贝,该拷贝包括相应数据在某个时间点(拷贝开始的时间点)的映像。快照可以是其所表示的数据的一个副本,也可以是数据的一个复制品。
需要注意的是:快照是完全可用的拷贝,但不是一份完整的拷贝。
存储快照的使用场景
场景一:
存储快照,是一种数据保护措施,可以对源数据进行一定程度的保护,通俗地讲,可以理解为—-后悔药。

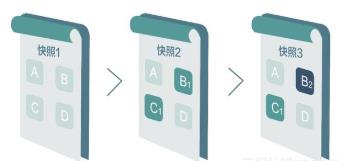
如上图,假设在t0时刻,有一份完整的源数据,我们在t1时刻,针对这份源数据创建一份快照。
t2时刻,若因为各种原因(误操作、系统错误等)导致源数据损毁,那么,我们可以通过回滚(rollback)快照,将源数据恢复至快照创建时的状态(即t1时刻),这样,可以尽量降低数据损失(损失的数据,是t1到t2之间产生的数据)。
这种功能,常用于银行、公安户籍、科研单位等。操作系统、软件升级或机房设备更替,一般会选择在夜间或其他无生产业务时,进行高危操作,操作前会对数据进行快照,若操作失败,则将快照进行rollback,将源数据恢复至操作前的状态。
场景2:
前言中说过,快照是一份完全可用的副本,那么,它完全可以被上层业务当做源数据。
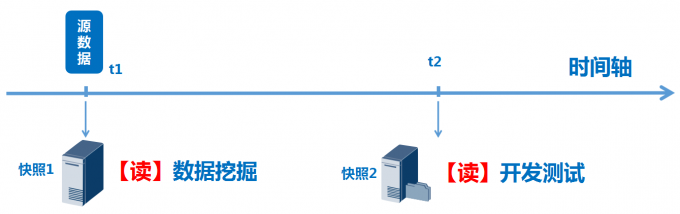
如上图,针对源数据,创建快照后,将快照卷映射给其他上层业务,可以用于数据挖掘和开发测试等工作,针对快照的读操作不影响源卷的数据。
这种功能,常用于直播(视频&图片)鉴黄、科研数据模拟开发测试等,比如,视频直播平台需要将某一段时间的视频提供给执法机构进行筛查分析,那么可以通过对特定时间点保存的数据创建快照,将快照映射给执法机构的业务主机去进行挖掘分析。
存储快照的实现原理
目前存储快照的实现方式均由各个厂商自行决定,但主要技术分为2类,一种是写时拷贝COW(Copy On Write),另一种,是写重定向ROW(Redirect On Write)。
关于这两种方式的流程可以参考文章:https://www.cnblogs.com/qcloud1001/p/9322321.html
- 写时拷贝COW
COW(Copy-On-Write),写时拷贝,也称为写前拷贝。
创建快照以后,如果源卷的数据发生了变化,那么快照系统会首先将原始数据拷贝到快照卷上对应的数据块中,然后再对源卷进行改写。
- 写时重定向ROW
ROW(Redirect-on-write ),也称为写时重定向。
创建快照以后,快照系统把对数据卷的写请求重定向给了快照预留的存储空间,直接将新的数据写入快照卷。上层业务读源卷时,创建快照前的数据从源卷读,创建快照后产生的数据,从快照卷读。
- 两种快照技术的优缺点
COW最大的问题是对写性能有影响。第一次修改原卷,需要复制数据,因此需要多一次读写的数据块迁移过程。这个就比较要命,应用需要等待时间比较长。但原卷数据的布局没有任何改变,因此对读性能没有任何影响。
ROW最大的问题是对读性能影响比较大。 ROW写的时候性能基本没有损耗,只是修改指针,实现效率很高。但多次读写后,原卷的数据就分散到各个地方,对于连续读写的性能不如COW。
LevelDB中的快照
先看下LevelDB中快照的数据结构:
1 |
|
通过快照的实现类,可以发现LevelDB中的快照是通过sequence_number_来实现的。在LevelDB中每次来一个新的更新类请求(put/del),都会生成一个独一无二的且递增的sequence_number,并把这个sequence_number同原始的key编码(其实还有具体的操作类型put/del)到一个新的key中。当两个key是一样的,就可以通过sequence_number来区分新旧,并且在读的时候默认是返回最新的数据。LevelDB中快照SnapShot类的实现原理就是,当调用函数获取一个快照时,就获取目前的sequence number,当读取数据时,只读取小于等于这个序列号的记录,这样就可以读取这个快照时间点之前的数据了。
LevelDB通过双向循环链表来保存多个快照。每生成一个快照时,要插入双向链表中,链表源码如下:
1 | class SnapshotList { |
dummy是不存实际有用信息的头节点,dummy.prev是最新的节点,dummy.next为最“老”的节点。当插入快照时,往dummy之前插入;删除快照时,则删除dummy.next节点。
LevelDB中对快照的调用
在DBImpl类定义了一个SnapshotList类型的成员变量snapshots_,用该变量来进行所有快照的管理,当调用db->GetSnapshot()时,其实就是用上一个序列号生成一个快照,并且插入快照链表里。
1 | const Snapshot* DBImpl::GetSnapshot() { |
当调用db->ReleaseSnapshot(readoptions.snapshot)时,其实就是调用SnapshotList的delete方法,将传入的快照删除。
1 | void DBImpl::ReleaseSnapshot(const Snapshot* s) { |
综上,当进行读取操作
- 首先判断是否定义了readoption.snapshot,如果定义了,那么就按这个快照读取数据;
- 如果没有定义,那么就用上一个序列号(last_sequence)作为快照序列号来读取数据。
也就是在没有定义快照操作时,因为用上一个序列号(last_sequence)作为快照序列号来读取数据,所以此时读取操作是读取最新的数据。
快照和备份的区别
快照是数据存储的某一时刻的状态记录;备份则是数据存储的某一个时刻的副本。快照与备份是两个完全不同的概念。
快照和备份的不同在于:
- 备份的数据安全性更好:如果原始数据损坏(例如物理介质损坏,或者绕开了快照所在层的管理机制对锁定数据进行了改写),快照回滚是无法恢复出正确的数据的,而备份可以。
- 快照的速度比备份快得多:生成快照的速度比备份速度快的多。也因为这个原因,为了回避因为备份时间带来的各种问题(例如IO占用、数据一致性等)很多备份软件是先生成快照,然后按照快照所记录的对应关系去读取底层数据来生成备份。
- 占用空间不同:备份会占用双倍的存储空间,而快照所占用的存储空间则取决于快照的数量以及数据变动情况。极端情况下,快照可能会只占用1%不到的存储空间,也可能会占用数十倍的存储空间。(PS:不过如果同一份数据,同时做相同数量的快照和增量备份的话,备份还是会比快照占用的存储空间多得多。)
更多问题
- 上层是怎么运用LevelDB中的快照的呢?
例子:
1 | #include<iostream> |
由于使用了快照,所有上面程序的输出结果将会是快照之前的值apple。
那么SSDB中是如何使用LevelDB提供的快照功能的呢?

