
本文主要内容如下:
- SeaweedFS架构
- Master Server API
- Volume Server API
- TTL特性
- EC特性
- Filer
- Mount
架构
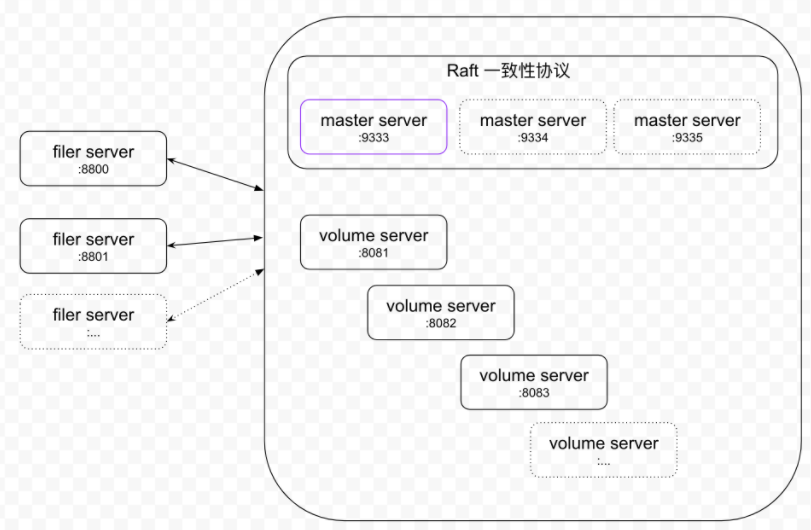
SeaweedFS的架构中包含两个组件:
- 数据存储集群(Volume Server Cluster)
Volume Server Cluster中每个volume server对应一个磁盘,每个磁盘有一系列的volume文件,每个volume文件默认大小为30GB,用于存储小对象。
每个volume文件对应一个index文件,用于记录volume中存储的小对象的偏移和长度,在volume server 启动时缓存在内存中。
这也是Haystack的一个重要设计思想,它做了一个两级的元数据映射,第一级把它映射到一个大文件,这样文件系统本身的元数据开销是很小的。第二次映射的时候,只需要在大文件内部去找它的偏移和长度。
而且做完两级映射之后,可以使大文件里对应的小文件的元数据全部缓存在内存里面,这样就可以大大提高它的查找的效率。
- Master Server Cluster
Master Server Cluster运行的是raft协议,维护集群的一致性状态,一般与volume server混合部署。volume server会向它上报自己的状态,然后它能够维护整个volume server cluster的拓扑。
同时它还负责对象写入时volume server的分配,以及负责数据读取时volume id到volume server地址映射。
Master Server和Volume Server
架构非常简单,数据存储在存储节点上的volumes里。一个volume server有多个volumes,并支持带基本验证的读写访问。
所有的volumes由master server管理。Master server有volume id到volume server的映射表。这是相当静态的信息,并且容易缓存。
当发生写请求的时候,master server会生成一个file key(一个递增的64位的无符号整数)。
写文件和读文件
Client发送一个写文件的请求,master server 为该文件返回其对应的(volume id, file key, file cookie, volume node url)。Client连接volume node并且POST 该文件。
当client需要读一个文件(使用volume id, file key, file cookie),通过volume id向master server获取(volume node url, volume node public url), 或者直接到缓存中获取,然后client就可以GET到文件内容。
FileId
Fid: 3,01637037d6
3表示volume id 32位无符号整数
01表示file key 64位无符号整数
637037d6表示file cookie 32位无符号整数
File key和file cookie均是以16进制表示,fid可以以
存储大小
当前的实现,每个volume 32GB(8 x 2^32 bytes). 8 bytes对齐的
可以有4 gibibytes(4GB)volumes
8 x 4GB x 4GB = 128 EB
每个文件大小限制最多就是单个volume大小。
复本策略
SeaweedFS支持复本配置。不过其复本配置并不是基于文件层级的,而是基于volume的
复本类型的释义:
| Value | Meaning |
|---|---|
| 000 | 没有冗余复本,就一份 |
| 001 | 在同一个rack上有一个复本 |
| 010 | 在同一个数据中心的不同rack上有一个复本 |
| 100 | 在不同的数据中心上有一个复本 |
| 200 | 两个复本在另外两个不同数据中心上 |
| 110 | 一个复本在不同rack上,一个复本在另一个数据中心 |
| … | … |
所有复本类型xyz表示:
| Column | Meaning |
|---|---|
| x | 在其他数据中心的复本数量 |
| y | 在同一个数据中心不同rack上的复本数量 |
| z | 在同一个rack上的不同server上的复本数量 |
说明:x,y,z的取值可以是0,1,2。所以有9种可能复本类型。
Master Server API
可以在HTTP API后面添加“&pretty=y”来得到一个json格式的输出。
分配一个file key
Basic Usage:
curlhttp://localhost:9333/dir/assign
查询volume
1 | curl "[http://localhost:9333/dir/lookup?volumeId=3&pretty=y](http://localhost:9333/dir/lookup?volumeId=3&pretty=y)" |
预分配volumes
一个volume 一次服务一个写请求,如果你需要增加并发,可以预分配许多volumes:
specify a specific replication
curl “http://localhost:9333/vol/grow?replication=000&count=4“
{“count”:4}# specify a collection
curl “http://localhost:9333/vol/grow?collection=turbo&count=4"#specify data center
curl “http://localhost:9333/vol/grow?dataCenter=dc1&count=4"#specify ttl
curl “http://localhost:9333/vol/grow?ttl=5d&count=4“
产生4个空的volumes
检查系统状态
1 | curl "[http://10.0.2.15:9333/cluster/status?pretty=y](http://10.0.2.15:9333/cluster/status?pretty=y)" |
Volume Server API
上传文件
curl -F file=@/home/chris/myphoto.jpghttp://127.0.0.1:8080/3,01637037d6
{“size”: 43234}
返回的size值是存储在seaweedfs上的大小,有时候文件会基于MIME类型被自动压缩。
删除文件
curl -X DELETEhttp://127.0.0.1:8080/3,01637037d6
检查volume server状态
1 | curl "[http://localhost:8080/status?pretty=y](http://localhost:8080/status?pretty=y)" |
存储文件以Time To Live(TTL)的方式
怎样使用
比如我们存一个文件其TTL位3分钟。
首先,向master请求分配一个file id 到一个有3分钟TTL的volume:
curlhttp://localhost:9333/dir/assign?ttl=3m
{“count”:1,”fid”:”5,01637037d6”,”url”:”127.0.0.1:8080”,”publicUrl”:”localhost:8080”}
然后,使用该file id把文件存储到volume server上
curl -F “file=@x.go“http://127.0.0.1:8080/5,01637037d6?ttl=3m
写成功之后,该文件在TTL时间耗尽前,可以正常被读到,但是如果TTL时间耗尽了,会报告文件没有并且返回http status为not found
高级用法
不要求文件的TTL与volume的TTL必须一样,只需要保证volume 的TTL比文件的TTL大就可以了。
支持的TTL格式
格式是一个整数跟着一个单位,单位可以是分钟,小时,天,周,月,年。
支持的TTL格式例子:
- 当分配file key的时候,master会选一个匹配TTL的TTL volume,如果没有匹配的TTL volume就创建一个新的
- Volume servers写入的文件将会带有失效时间,当达到失效时间后,获取文件将会报告文件not found.
- Volume servers将会跟踪记录每一个volume的最大失效时间,如果一个volume失效后便停止向master server报告
- (没有向master server报告volume)master server会认为先前存在的volumes是死的,并且不再向这些volumes分配请求
- 在大约10% TTL时间或者最多10分钟后,volume servers将会删除过期的volume
部署
对于生产部署环境,TTL volume 的最大size是需要考虑的。如果写非常频繁,TTL volume 将很快增长到max volume size,所以当磁盘空间不充足的时候,最好减小最大volume size。
不推荐将TTL volumes 和非TTL volumes部署在同一个集群中,这是因为volume max size默认是30GB,是在volume master上以集群level配置的。(这就是说30GB这个默认max size的配置是针对整个cluster的,而不是单个volume)
我们可以实现为每一个TTL配置一个max volume size的功能,然而这可能相当繁琐,可能在以后有强烈的需求后会去着手实现。
个人解读:由于volume max size这一配置是针对整个集群而设置的,不能对单个volume额外设置其max size。而TTL volume的max size通常由于空间原因不用设置到30GB,所以不推荐将TTL volumes 和非TTL volumes部署在同一个集群中。
Master server故障转移
Master servers之间使用raft协议来选主,主负责所有的任务,比如管理volumes,分配file id。
如果主挂了,将会选举出新的主。所有的volume servers将会发生他们的心跳以及他们的volumes信息给新的主。
在转移的过程中,可能有片刻时间,新的主只有所有volume servers的部分信息。这就意味着那些还没有上报心跳的volume servers将暂时不可写。
常规的启动多个多个master servers和多个volume servers的方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18weed master -port=9333 -mdir=./1 -peers=localhost:9333,localhost:9334,localhost:9335
weed master -port=9334 -mdir=./2 -peers=localhost:9333,localhost:9334,localhost:9335
weed master -port=9335 -mdir=./3 -peers=localhost:9333,localhost:9334,localhost:9335# now start the volume servers, specifying any one of the master server
weed volume -dir=./1 -port=8080 -mserver=localhost:9333,localhost:9334,localhost:9335
weed volume -dir=./2 -port=8081 -mserver=localhost:9333,localhost:9334,localhost:9335
weed volume -dir=./3 -port=8082 -mserver=localhost:9333,localhost:9334,localhost:9335
//The full list of masters is recommended, but not required.
//You can only specify any master servers.
weed volume -dir=./3 -port=8082 -mserver=localhost:9333
weed volume -dir=./3 -port=8082 -mserver=localhost:9333,localhost:9334
FAQ:可以向正在运行的seaweedfs集群中添加一个新的master server吗?
A:可以把master 看做zookeeper节点,并且不要去经常变动。要添加一个master,需要停所有现有的master,然后以新的master列表启动新的masters。
支持EC特性
支持EC 10+4:即把数据切分成10个原始分片,然后计算出4个校验分片,最多容忍4个分片丢失。
优点:
● 存储效率
● 高可用
● 灵活的服务器布局
缺点:
● 如果有EC分片丢失,获取这些数据将会慢一些
● 重构丢失的EC分片可能会需要转移整个volume的数据
● 只支持删除操作,不支持更新
目前支持EC 10+4可以通过修改代码来支持其他EC模式:https://github.com/chrislusf/seaweedfs/blob/master/weed/storage/erasure_coding/ec_encoder.go#L17
怎么配置生效
运行
1 |
|
输出:
1 |
|
把输出放到文件master.toml中,并将文件放到~/.seaweedfs/或者/etc/seaweedfs/目录下。
输出是一些周期执行的命令,这些命令可以通过weed shell执行,效果也一样。把命令放到文件master.toml中是为了部署方便。
在文件master.toml中的命令是在master上执行的。如果你有大量的EC volumes,在master上处理他们可能消耗一些CPU资源,最好在另一个机器上通过cron 任务用weed shell来执行这些命令。
3个与EC相关的步骤:
Erasure Encode Sealed Data EC编码封存数据
ec.encode命令将会找那些几乎满了的volume并且有一段时间都没有活动的volume。
默认的命令是 ec.encode -fullPercent=95 -quietFor=1h。它会找至少95% x max volume size,通常是30GB,并且有一个小时都没有更新的volume。
数据修复
数据修复的默认命令是 ec.rebuild -force
数据修复是针对整个volume的,而非单个文件,这样重建丢失的数据分片是比处理单个文件更高效并且更快。
EC数据均衡
随着服务器的添加或者移除,一些数据分片可能就不是最佳布局了。比如,一个volume的5个分片可能是在同一个服务器上,如果该服务器挂掉,那么该volume将会是不可修复的或者说部分数据是永久丢失。
默认的命令是ec.balance -force,该命令会尝试将数据分片尽量均匀分布以减小数据丢失的风险。
Filer
文件管理器,Filer将数据上传到Weed Volume Servers,并将大文件分成块,将元数据和块信息写入Filer存储区(Filer Store)。
为了获取所有volumes的位置更新,Filer有一个持久化的client连接到master。
对于读文件:
- Filer从Filer Store中查询元数据,Filer Store可能是Cassandra/Mysql/Postgres/Redis/LevelDB。
Filer 从volume server中读数据并返回给读请求。
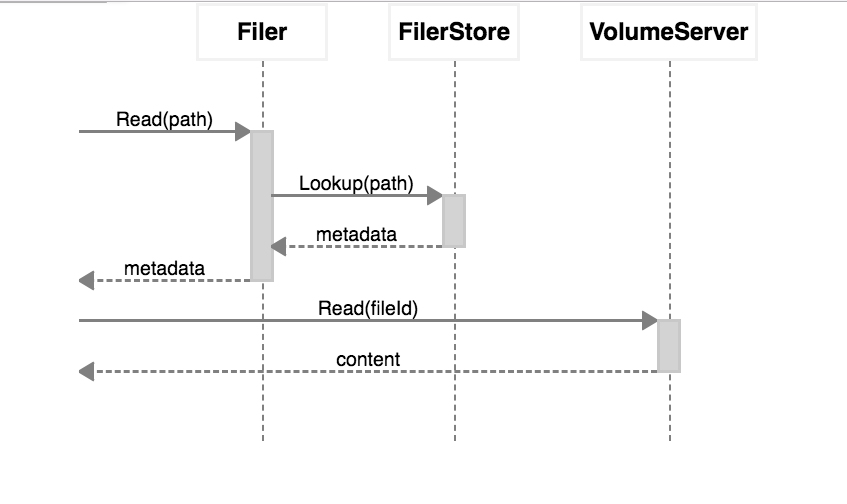
对于写文件:Client将文件发送到Filer
- Filer上传数据到volume servers, 并且将大文件切分成chunks
- Filer把元数据和chunk信息写到Filer Store
Filer Store
各种Filer Store的比较
| Filer Store Name | Lookup | number of entries in a folder | Scalability | Renaming | TTL | Note |
|---|---|---|---|---|---|---|
| memory | O(1) | limited by memory | Local, Fast | for testing only, no persistent storage | ||
| leveldb | O(logN) | unlimited | Local, Very Fast | Default, fairly scalable | ||
| leveldb2 | O(logN) | unlimited | Local, Very Fast, faster than leveldb | Similar to leveldb, part of the lookup key is 128bit MD5 instead of the long full file path | ||
| Redis | O(1) | limited | Local or Distributed, Fastest | Yes | one directory’s sub file names are stored in one key~value entry | |
| Cassandra | O(logN) | unlimited | Local or Distributed, Very Fast | Yes | ||
| MySql | O(logN) | unlimited | Local or Distributed, Fast | Atomic | Easy to manage, export | |
| Postgres | O(logN) | unlimited | Local or Distributed, Fast | Atomic | Easy to manage, export |

