
标准校验
在GNU/Linux中,有许多的文件系统检测工具来检测磁盘上数据的完整性。通常是通过“fsck”工具完成的。然而,该工具有几个主要缺点。
首先,如果您打算修复数据错误,则必须脱机fsck磁盘,这意味着停机时间。因为在执行fsck之前,必须使用“umount”命令卸载磁盘。对于根分区,这进一步意味着要从其他介质(如CDROM或u盘)启动。停机时间的长短跟磁盘容量大小有关,大容量的磁盘在修复时,其停机时间可能长达几小时。
其次,诸如ext3或ext4的文件系统,对底层数据结构(如LVM或RAID)一无所知。您可能在一个磁盘上只有一个坏块,但在另一个磁盘上有一个好的块。不幸的是,Linux软件RAID从ext3的角度或ext4,不知道哪一块数据是好的,哪一块数据是坏的,它可能得到好的数据如果从磁盘读取到包含好的数据的块;也可能得到损坏的数据如果从磁盘读到那个坏块。这个过程没有从哪块磁盘读取数据的控制,也没有修复损坏的数据。这些错误被称为“静默数据错误”,使用标准的GNU/Linux文件系统对此类错误实际上无能为力。
ZFS Scrubbing(ZFS数据清理)
在Linux上使用ZFS,可以通过磁盘数据清理来检测和纠正静默数据错误。这在技术上类似于ECC RAM,如果错误驻留在ECC DIMM中,您可以找到另一个包含好的数据的寄存器,并使用它来修复坏寄存器。这是一种已经使用了一段时间的老技术,所以令人惊讶的是,在日志文件系统的标准套件中没有这种技术。此外,就像您可以在不停机的情况下在实时运行的系统上清除ECC RAM一样,有了ZFS,您也可以能够在不停机的情况下进行磁盘数据清理。
译者注:也就是说ZFS Scrubbing是ZFS的一种数据清理手段,主要用途是用来修复由于磁盘静默故障导致的数据损坏
当ZFS对您的存储池进行数据清理(scrub)时,它将根据其已知的校验值和逐一检查存储池中的每个块。默认情况下,从上到下的每个块都使用适当的算法进行校验。当前是使用的“fletcher4”算法,它是256位的算法,速度很快。当然你也可以更改为使用SHA-256算法,但不推荐这样做,因为计算SHA-256校验和的开销比fletcher4更大。然而,由于SHA-256,您有1 / 2^256或1 / 10^77的概率损坏块哈希到相同的SHA-256校验值。这个概率是0.00000000000000000000000000000000000000000000000000000000000000000000000000001%。作为参考,使用市场上最可靠的硬件,未经校正的ECC内存错误将更频繁地发生的概率是这个概率的约50个数量级。所以当你清理数据时,这个概率是要么校验和匹配,你大概率有一个好的数据块,要么不匹配,你有一个损坏的数据块。
ZFS存储池中数据清理不是自动发生的事情。你需要手动去做,并且强烈建议你定期去做。推荐的数据清理的频率取决于底层磁盘的质量。如果您使用的是SAS或FC硬盘,那么每月一次就足够了。如果你使用的是消费级的SATA或SCSI,你应该每周做一次。你可以使用以下命令轻松地安排一次数据清理:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22# zpool scrub tank
# zpool status tank
pool: tank
state: ONLINE
scan: scrub in progress since Sat Dec 8 08:06:36 2012
32.0M scanned out of 48.5M at 16.0M/s, 0h0m to go
0 repaired, 65.99% done
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
sde ONLINE 0 0 0
sdf ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
sdg ONLINE 0 0 0
sdh ONLINE 0 0 0
mirror-2 ONLINE 0 0 0
sdi ONLINE 0 0 0
sdj ONLINE 0 0 0
errors: No known data errors
如您所见,您可以在执行数据清理的过程中获取它的状态。执行擦除操作会严重影响磁盘性能。因此,如果出于任何原因需要停止scrub,可以将”-s”参数传递给scrub子命令。但是,一般情况应该让数据清理继续完成。1
zpool scrub -s tank
你也可以在你的root用户的crontab中放入类似以下内容,这样将在每周日凌晨02:00执行一次数据清理:1
0 2 * * 0 /sbin/zpool scrub tank
数据的自愈
如果您的存储池正在使用某种冗余,那么ZFS不仅会在一次数据清理中检测到静默数据错误,如果另一个磁盘上存在好的数据时,还会去纠正这些错误。这就是所谓的“自愈”,如下图所示。在前面的介绍RAIDZ的文章中,讨论了如何使用RAIDZ修复数据。我要简化一下,用一个两路镜像。假设一个应用程序需要一些数据块,而在这些数据块中,有一些数据块损坏了。ZFS如何知道数据已损坏? 正如前面所述,通过检查块的SHA-256校验值。如果一个块的校验值不匹配,它将查看镜像中的其他磁盘,看看是否能找到一个好的块。如果能找到,则将好的块传递给应用程序,然后ZFS将修复镜像中的坏块,以便它可以通过SHA-256校验。这样应用程序将始终获得好的数据,而您的存储池将始终处于良好、干净、一致的状态。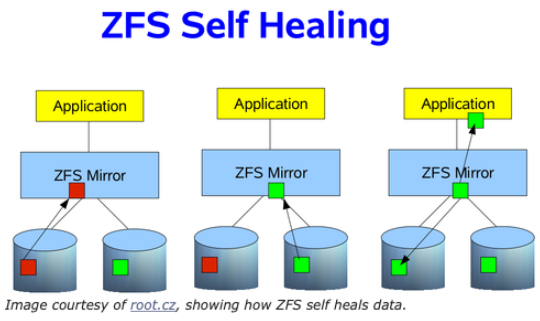
Resilvering Data(重建数据)
Resilvering data跟重建数据或者重新同步数据到磁盘阵列中的新盘的概念是一样的。然而在Linux 软件RAID,硬件RAID控制器以及其他RAID实现,活动的块(有数据的块)和没有数据的块是无法区分的。所以,这种重建将会从磁盘开头开始,直到磁盘的末尾才结束(也就是这种情况下重建,是整个磁盘重建,这样可能会做大量的无用功)。因为ZFS知道RAID结构和文件系统的元数据,所以ZFS在重建数据这块会比较灵活,而不会浪费时间在没有数据的磁盘上,只需要关心有数据的地方。如果您的存储池只被部分填满,那么这可以大大节省时间(因为不需要整个存储池重建)。如果池只被填满了10%,那么这意味着只在10%的磁盘上工作。因此,为了区别与传统的数据重建,对于ZFS,我们需要一个新的术语,而不是“重建”、“重新同步”或“重建”。在本例中,我们将重建数据的过程称为“resilvering”。
不幸的是,磁盘会坏,并需要更换。如果您的存储池中有冗余,并且能够承受某种程度的故障,那么您仍然可以向应用程序发送数据和从应用程序接收数据,即使存储池处于“降级”模式。如果您的运行的系统中有昂贵的支持热插拔的磁盘,那么您可以在不停机的情况下更换磁盘(您很幸运)。如果不是,您仍然需要识别坏盘,并替换它。如果您的磁盘池中有许多磁盘(比如24个),那么这可能是一件苦差事。然而,大多数GNU/Linux操作系统供应商,如Debian或Ubuntu,提供了一个名为“hdparm”的工具,它允许您发现存储池中所有磁盘的序列号。当然,磁盘控制器通常也会将这些信息呈现给Linux内核。所以,你可以执行如下命令:1
2
3
4
5
6
7
8# for i in a b c d e f g; do echo -n "/dev/sd$i: "; hdparm -I /dev/sd$i | awk '/Serial Number/ {print $3}'; done
/dev/sda: OCZ-9724MG8BII8G3255
/dev/sdb: OCZ-69ZO5475MT43KNTU
/dev/sdc: WD-WCAPD3307153
/dev/sdd: JP2940HD0K9RJC
/dev/sde: /dev/sde: No such file or directory
/dev/sdf: JP2940HD0SB8RC
/dev/sdg: S1D1C3WR
看起来/dev/sde是坏盘。系统里有所有其他磁盘的序列号,但唯独/dev/sde没有。所以,通过排除,我可以到存储阵列,找到哪个序列号没有被打印出来。那就是坏盘。在这个例子中,我找到序列号“JP2940HD01VLMC”。我拔出磁盘,将其替换为一个新的磁盘,并查看是否重新填充了/dev/sde,并且其他的磁盘仍然在线。如果是,那么我已经找到了我的磁盘,可以将它添加到池中。实际上,在我的个人管理程序上,这种情况已经发生过两次了。更换起来很容易,不到10分钟就重新online了。
要用新磁盘替换存储池中的坏盘,可以使用”replace”子命令。假设新磁盘也将自己标识为/dev/sde,那么我将用以下命令:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22# zpool replace tank sde sde
# zpool status tank
pool: tank
state: ONLINE
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scrub: resilver in progress for 0h2m, 16.43% done, 0h13m to go
config:
NAME STATE READ WRITE CKSUM
tank DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
replacing DEGRADED 0 0 0
sde ONLINE 0 0 0
sdf ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
sdg ONLINE 0 0 0
sdh ONLINE 0 0 0
mirror-2 ONLINE 0 0 0
sdi ONLINE 0 0 0
sdj ONLINE 0 0 0
resilver类似于Linux软件RAID的重建。它正在新磁盘上重建数据块,直到镜像(在本例中)处于完全健康状态。查看resilver的状态将帮助您了解resilver何时将完成。
识别存储池的问题
通过传递“-x”参数,可以快速确定存储池一切是否正常运行,而不需要“zpool status”命令的完整输出。这对于脚本在没有复杂逻辑的情况下进行解析很有用,并且在出现故障时可以发出警告:1
2# zpool status -x
all pools are healthy
“zpool status”命令结果中的每一字段,都为您提供关于池的重要信息,其中大部分字段的含义是不言自明的。它们的定义如下:
- pool – 存储池名字
- state – 存储池当前的健康状态。 此信息仅指存储池提供必要复制级别的能力。
- status – 对存储池问题的描述。如果没有发现问题,则省略此字段。
- action – 修复错误的建议操作。该字段是一个缩写表单,引导用户进入以下部分之一。如果没有发现问题,则省略此字段。
- see – 包含详细修理信息的知识文章的参考。在线文章的更新比本指南的更新更频繁,并且应该经常参考最新的修理程序。如果没有发现问题,则省略此字段。
- scrub – 标识一个数据清理操作的当前状态,这可能包括最近一次数据清理操作完成的日期和时间、正在进行的数据清理的当前状态,或者没有如果没有请求数据清理的话。
- errors – 标识已知数据错误或不存在已知数据错误。
- config – 描述组成池的设备的配置布局,以及它们的状态和从设备生成的任何错误。状态包括:ONLINE、FAULTED、DEGRADED、UNAVAILABLE和OFFLINE。如果状态不是ONLINE,则池的容错能力已被破坏。
zpool status命令输出结果的列,比如“READ”、“WRITE”和“CHKSUM”的定义如下:
- NAME – 存储池中每个VDEV的名称,按嵌套顺序显示。
- STATE – 池中每个VDEV的状态。状态可以是上面介绍的“config”中的任何一种状态。
- READ – 发出读请求时发生的I/O错误。
- WRITE – 在发出写请求时发生的I/O错误。
- CHKSUM – 校验错误。设备返回损坏的数据作为读请求的结果。
scrub和resilver data的区别
简单的来说,scrub可以理解为数据扫描并修复损坏数据,在扫描的过程中,会去校验数据是否有损坏,发现数据有损坏,会去修复数据,这个修复是在数据损坏的盘上修复,不用替换硬盘。
resilver data可以理解为重建数据,重建的过程需要一个新的盘,把数据重建(恢复)到新盘的过程,这个叫resilver data。但是跟传统的重建数据不同,这个resilver data不是全盘重建。
所以scrub和resilver data是两个不同的概念,而且适用场景和用途也不同。
总结
定期扫描数据进行数据清理将确保存储池中的数据保持一致。尽管数据扫描(数据清理)可能会给正在读写数据的应用程序带来压力,但它可以在未来避免更大的麻烦。 此外,由于您随时可能有一个“损坏的设备”(有关使用ZFS的损坏设备,请参阅http://docs.oracle.com/cd/E19082-01/817-2271/gbbvf/index.html),因此正确地了解如何修复该设备,以及在更换一个设备时将会发生什么,这对存储管理至关重要。当然,关于这个主题,我还有很多可以讨论的内容,但这篇文章至少让您了解了数据清理(scrub data)和重建数据(resilver data)的概念。
参考资料
https://pthree.org/2012/12/11/zfs-administration-part-vi-scrub-and-resilver/

