本文介绍ZFS的基础和核心,被称为“ZFS数据集”或者文件系统。前面的文章,我们一直在讨论如何管理存储池。但是存储池并不意味着直接存储数据。相反,我们应该创建共享相同存储系统的文件系统。从现在开始,我们将这些文件系统称为数据集。
背景
首先,在全面理解ZFS数据集之前,我们需要了解GNU/Linux中,传统的文件系统和卷管理是如何工作的。为了公平地对待这一点,我们需要将Linux软件RAID、LVM和ext4或另一个Linux内核支持的文件系统组装在一起。
这是通过创建冗余磁盘阵列,并导出块设备来表示该阵列来实现的。然后,使用LVM对导出的块设备进行格式化。如果我们有多个RAID阵列,我们也会对它们进行格式化。然后我们将所有这些导出的块设备添加到一个“卷组”中,该卷组表示我的池存储。如果我有5个导出的RAID阵列,每个阵列1TB,那么在这个卷组中就有5TB的池存储。现在,我需要决定如何划分卷,以创建特定大小的逻辑卷。如果这是针对Ubuntu或Debian的安装,也许我会给根文件系统一个逻辑卷分配100GB。这100GB现在被标记为卷组所占用。然后我将500GB给我的主目录,等等。每个操作导出一个块设备,代表我的逻辑卷,我使用ext4或其它我选择的文件系统对这些块设备进行格式化。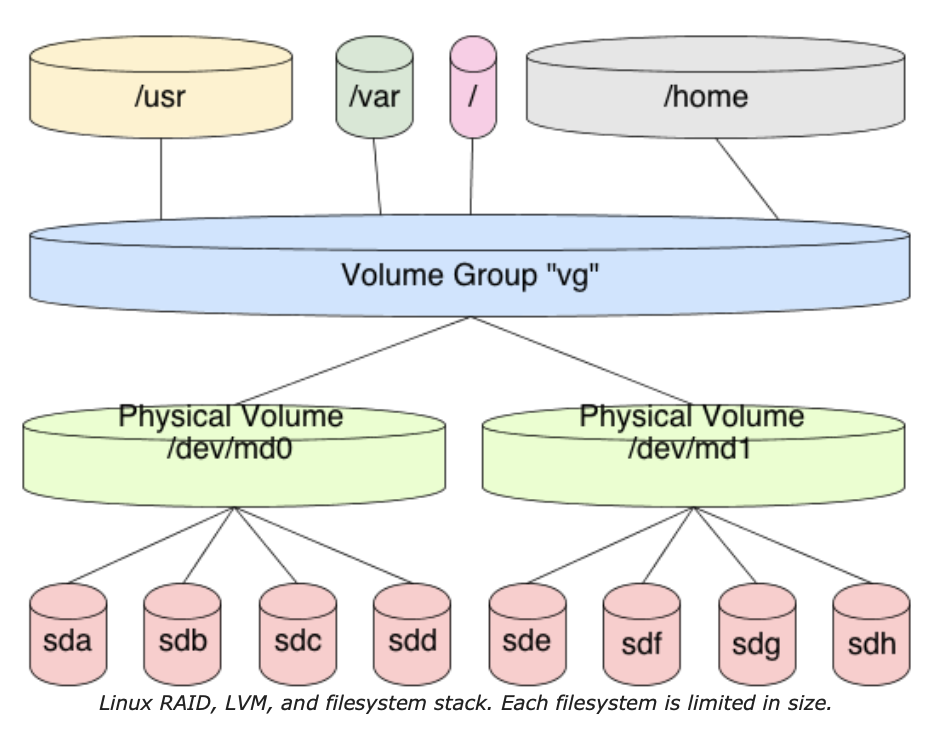
在这个场景中,卷组中的每个逻辑卷都是固定大小的。它无法处理已满的池。因此,在格式化逻辑卷块设备时,文件系统的大小是固定的。当该设备填满时,必须同时调整逻辑卷和文件系统的大小。这通常需要大量的命令,而且要在不丢失数据的情况下正确地进行操作是有难度的。
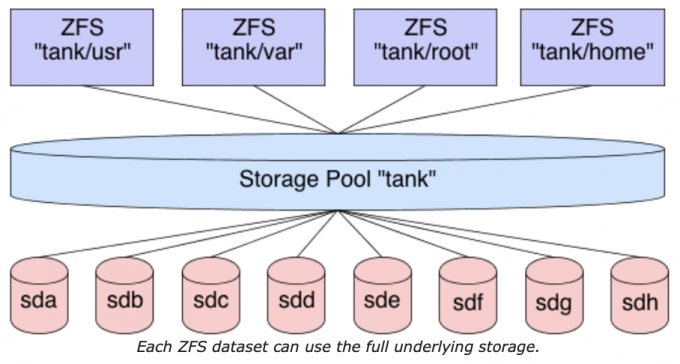
ZFS处理文件系统有点不同。首先,不需要用上面介绍的传统文件系统的方法来创建存储。前面的文章已经介绍了如何创建存储池zpool,现在我们将介绍如何使用它。这是通过在文件系统中创建数据集来实现的。默认情况下,该数据集将拥有对整个存储池的完全访问权。如果我们的存储池大小为5TB,如前所述,那么我们的第一个数据集将可以访问池中的所有5TB。如果我创建了第二个数据集,它也将完全访问池中的所有5TB,以此类推。
现在,当文件被放置在数据集中时,存储池将该文件所占有的存储标记为所有数据集不可用。这意味着每个数据集都知道池中哪些是可用的,哪些是池中所有其他数据集不可用的。不需要创建大小有限的逻辑卷。每个数据集都可以继续往存储池中放文件,直到池被填满。当然,您可以对数据集设置配额,限制它们的大小,或者导出ZVOLs,这些主题我们将在后面介绍。
好,接下来让我们来创建一些数据集。
基本创建
在接下来的这些示例中,假设我们的ZFS共享存储名为“tank”。此外,我们将假设在RAIDZ-1阵列中创建了4个预分配的文件,每个文件的大小为1GB。让我们在这些基础上创建一些数据集。1
2
3
4
5# zfs create tank/test
# zfs list
NAME USED AVAIL REFER MOUNTPOINT
tank 175K 2.92G 43.4K /tank
tank/test 41.9K 2.92G 41.9K /tank/test
注意,数据集“tank/test”在默认情况下被挂载到“tank/test”,并且它对整个池有完全的访问权限。还要注意,它只占用池的41.9 KB。让我们再创建4个数据集,然后看看输出:1
2
3
4
5
6
7
8
9
10
11
12# zfs create tank/test2
# zfs create tank/test3
# zfs create tank/test4
# zfs create tank/test5
# zfs list
NAME USED AVAIL REFER MOUNTPOINT
tank 392K 2.92G 47.9K /tank
tank/test 41.9K 2.92G 41.9K /tank/test
tank/test2 41.9K 2.92G 41.9K /tank/test2
tank/test3 41.9K 2.92G 41.9K /tank/test3
tank/test4 41.9K 2.92G 41.9K /tank/test4
tank/test5 41.9K 2.92G 41.9K /tank/test5
每个数据集自动挂载到其各自的挂载点,并且每个数据集可以完全自由地访问存储池。让我们在其中一个数据集中填充一些数据,看看这是如何影响底层存储的:1
2
3
4
5
6
7
8
9
10# cd /tank/test3
# for i in {1..10}; do dd if=/dev/urandom of=file$i.img bs=1024 count=$RANDOM &> /dev/null; done
# zfs list
NAME USED AVAIL REFER MOUNTPOINT
tank 159M 2.77G 49.4K /tank
tank/test 41.9K 2.77G 41.9K /tank/test
tank/test2 41.9K 2.77G 41.9K /tank/test2
tank/test3 158M 2.77G 158M /tank/test3
tank/test4 41.9K 2.77G 41.9K /tank/test4
tank/test5 41.9K 2.77G 41.9K /tank/test5
注意,在我的例子中,“tank/test3”占用了158 MB磁盘,因此根据其余的数据集,池中只有2.77 GB可用,而以前是2.92 GB。因此,正如您所看到的,这里最大的优点是我不需要担心预分配的块设备,就像使用LVM时一样。相反,ZFS管理整个堆栈,因此它了解有多少数据被占用,有多少数据可用。
Mounting 数据集
在创建数据集时,默认情况下并没有创建可导出的块设备,理解这一点很重要。这意味着您没有可以直接挂载的东西。总之,没有任何东西可以添加到/etc/fstab文件中以便持久化,重启后也会自动挂载。
那么,如果没有什么要添加的,那么如何挂载文件系统呢? 如果确实需要的话,这是通过导入池,然后运行“zfs mount”命令来完成的。类似地,我们有一个”zfs unmount”命令来卸载数据集,或者我们可以使用标准的”umount”工具:1
2
3
4
5
6
7
8
9
10
11
12
13# umount /tank/test5
# mount | grep tank
tank/test on /tank/test type zfs (rw,relatime,xattr)
tank/test2 on /tank/test2 type zfs (rw,relatime,xattr)
tank/test3 on /tank/test3 type zfs (rw,relatime,xattr)
tank/test4 on /tank/test4 type zfs (rw,relatime,xattr)
# zfs mount tank/test5
# mount | grep tank
tank/test on /tank/test type zfs (rw,relatime,xattr)
tank/test2 on /tank/test2 type zfs (rw,relatime,xattr)
tank/test3 on /tank/test3 type zfs (rw,relatime,xattr)
tank/test4 on /tank/test4 type zfs (rw,relatime,xattr)
tank/test5 on /tank/test5 type zfs (rw,relatime,xattr)
默认情况下,数据集的挂载点为”/\1
2
3
4
5
6
7
8# zfs set mountpoint=/mnt/test tank/test
# mount | grep tank
tank on /tank type zfs (rw,relatime,xattr)
tank/test2 on /tank/test2 type zfs (rw,relatime,xattr)
tank/test3 on /tank/test3 type zfs (rw,relatime,xattr)
tank/test4 on /tank/test4 type zfs (rw,relatime,xattr)
tank/test5 on /tank/test5 type zfs (rw,relatime,xattr)
tank/test on /mnt/test type zfs (rw,relatime,xattr)
嵌套数据集
数据集不需要被隔离。您可以在彼此之间创建嵌套的数据集。这允许您在不影响其他目录结构的情况下创建命名空间,同时调优嵌套目录结构。例如,你可能想压缩/var/log,而不是父文件/var。它还有其他的好处,还有一些我们将在后面介绍的注意事项。
要创建嵌套数据集,请像创建其他数据集一样,提供父存储池和数据集。在下面的例子中,我们将在test数据集中创建一个嵌套的log数据集:1
2
3
4
5
6
7
8
9
10# zfs create tank/test/log
# zfs list
NAME USED AVAIL REFER MOUNTPOINT
tank 159M 2.77G 47.9K /tank
tank/test 85.3K 2.77G 43.4K /mnt/test
tank/test/log 41.9K 2.77G 41.9K /mnt/test/log
tank/test2 41.9K 2.77G 41.9K /tank/test2
tank/test3 158M 2.77G 158M /tank/test3
tank/test4 41.9K 2.77G 41.9K /tank/test4
tank/test5 41.9K 2.77G 41.9K /tank/test5
数据集管理
除了创建数据集,当您不再需要它们时,还可以销毁它们。销毁数据集将释放块供其他数据集使用,销毁数据集后不能在没有快照的情况下还原,这一点我们将在后面介绍。销毁数据集命令如下:1
2
3
4
5
6
7
8
9# zfs destroy tank/test5
# zfs list
NAME USED AVAIL REFER MOUNTPOINT
tank 159M 2.77G 49.4K /tank
tank/test 41.9K 2.77G 41.9K /mnt/test
tank/test/log 41.9K 2.77G 41.9K /mnt/test/log
tank/test2 41.9K 2.77G 41.9K /tank/test2
tank/test3 158M 2.77G 158M /tank/test3
tank/test4 41.9K 2.77G 41.9K /tank/test4
如果需要,我们也可以重命名数据集。当数据集的用途发生变化,并且希望名称反映该用途时,这很方便。参数以source数据集作为第一个参数,以新名称作为后一个参数。例子是将数据集tank/test3 重命名为tank/music:1
2
3
4
5
6
7
8
9# zfs rename tank/test3 tank/music
# zfs list
NAME USED AVAIL REFER MOUNTPOINT
tank 159M 2.77G 49.4K /tank
tank/music 158M 2.77G 158M /tank/music
tank/test 41.9K 2.77G 41.9K /mnt/test
tank/test/log 41.9K 2.77G 41.9K /mnt/test/log
tank/test2 41.9K 2.77G 41.9K /tank/test2
tank/test4 41.9K 2.77G 41.9K /tank/test4
总结
本文帮助您开始理解ZFS数据集。还有许多与“zfs”命令相关的子命令可用,它们有许多不同的参数。你可以通过查看手册页以获得完整的清单。然而,本文并不是对数据集的深入彻底的掌握,随着我们对数据集的探索,更多的原则和概念将会浮出海面。最后,您应该足够熟悉数据集,从而能够以最小的努力管理整个存储的基础设施。
参考资料
https://pthree.org/2012/12/17/zfs-administration-part-x-creating-filesystems/

