压缩列表(ziplist)
- Redis中的压缩列表实现及特点
- Redis中的压缩列表源码难点分析
- Redis中的压缩列表源码部分节选
一、Redis中的压缩列表实现及特点
压缩列表是 Redis 为了节约内存而开发的, 由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构。
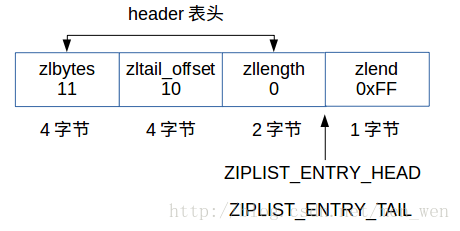
一个压缩列表可以包含任意多个节点(entry), 每个节点可以保存一个字节数组或者一个整数值。如下图(摘自《Redis设计与实现》):

其中字段含义如下:
- zlbytes:占4个字节,记录整个压缩列表占用的内存字节数
- zltail_offset:占4个字节,记录压缩列表尾节点entryN距离压缩列表的起始地址的字节数
- zllength:占2个字节,记录了压缩列表的节点数量
- entry[1-N]:长度不定,保存数据
- zlend:占1个字节,保存一个常数255(0xFF),标记压缩列表的末端。
1. 创建一个空的压缩列表
1 | /* Create a new empty ziplist. */ |
相关的宏定义1
2
3
4
5
6
7
一个空的压缩列表:
2. 压缩列表节点结构

压缩列表节点中的previous_entry_length
previous_entry_length 属性以字节为单位, 记录了压缩列表中前一个节点的长度。
previous_entry_length 属性的长度可以是 1 字节或者 5 字节:
- 如果前一节点的长度小于254字节, 那么 previous_entry_length 属性的长度为 1 字节: 前一节点的长度就保存在这一个字节里面
- 如果前一节点的长度大于等于254字节, 那么 previous_entry_length 属性的长度为 5 字节: 其中属性的第一字节会被设置为 0xFE (十进制值 254), 而之后的四个字节则用于保存前一节点的长度。
因此可以看到这段获取前一个节点长度的宏定义:1
2
3
4
5
6
7
8
9
10
11
12/* Decode the length of the previous element, from the perspective of the entry
* pointed to by 'ptr'. */
因为节点的 previous_entry_length 属性记录了前一个节点的长度, 所以程序可以通过指针运算, 根据当前节点的起始地址来计算出前一个节点的起始地址。
二、Redis中的压缩列表源码难点分析
1. 压缩列表节点中的encoding
压缩列表节点的 encoding属性记录了节点的 content 属性所保存数据的类型以及长度:
- 一字节、两字节或者五字节长, 值的最高位为 00 、 01 或者 10 的是字节数组编码: 这种编码表示节点的 content 属性保存着字节数组, 数组的长度由编码除去最高两位之后的其他位记录;
- 一字节长, 值的最高位以 11 开头的是整数编码: 这种编码表示节点的 content 属性保存着整数值, 整数值的类型和长度由编码除去最高两位之后的其他位记录;
表格中的下划线 _ 表示留空, 而 b 、 x 等变量则代表实际的二进制数据, 为了方便阅读, 多个字节之间用空格隔开。
字节数组编码:
| 编码 | 编码长度 | content保存的值长度 |
|---|---|---|
| 00bbbbbb | 1 字节 | 长度小于等于 2^6 −1 字节 |
| 01bbbbbb xxxxxxxx | 2 字节 | 长度小于等于 2^14 −1 字节 |
| 10______ aaaaaaaa bbbbbbbb cccccccc dddddddd | 5 字节 | 长度小于等于2^32 −1字节 |
整数编码:
| 编码 | 编码长度 | content保存的值 |
|---|---|---|
| 1100 0000 | 1 字节 | 16位有符号整数(int16_t 类型的整数) |
| 1101 0000 | 1 字节 | int32_t 类型的整数 |
| 1110 0000 | 1 字节 | int64_t 类型的整数表示的范围 |
| 1111 0000 | 1 字节 | 24位有符号整数表示的范围 |
| 1111 1110(0xfe) | 1 字节 | 8位有符号整数表示的范围 |
| 1111 xxxx | 1 字节 | 4位立即数介于0-12之间,无对应value,保存在encoding |
关于1111 xxxx编码:1111 xxxx 首先最小值应该是1111 0001(1111 0000已经被占用),最大值应该是1111 1101(1111 1110与1111 1111均已经被占用),因此可用的编码值只能是 1 至 13,由于还需要减1,所以实际只能编码[0,12]
Redis提供的有关字节数组和整数编码的宏定义:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16/* Different encoding/length possibilities */
//掩码个功能就是区分一个encoding是字节数组编码还是整数编码
//如果这个宏返回 1 就代表该enc是字节数组,如果是 0 就代表是整数的编码
下面这段代码主要是为了获取一个压缩列表节点所占用的长度。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55/* Extract the encoding from the byte pointed by 'ptr' and set it into
* 'encoding'. */
/* Decode the length encoded in 'ptr'. The 'encoding' variable will hold the
* entries encoding, the 'lensize' variable will hold the number of bytes
* required to encode the entries length, and the 'len' variable will hold the
* entries length. */
/* Decode the number of bytes required to store the length of the previous
* element, from the perspective of the entry pointed to by 'ptr'. */
/* Return the total number of bytes used by the entry pointed to by 'p'. */
static unsigned int zipRawEntryLength(unsigned char *p) {
unsigned int prevlensize, encoding, lensize, len;
ZIP_DECODE_PREVLENSIZE(p, prevlensize);
ZIP_DECODE_LENGTH(p + prevlensize, encoding, lensize, len);
return prevlensize + lensize + len;
}
ZIP_ENTRY_ENCODING中ZIP_STR_MASK为0xc0对应(1100 0000),小于0xc0的就表示编码为字节数组,大于0xc0的就表示编码为整数数组。需要注意的是,当encoding长度为5个字节时,表示的字节数组的长度由低32位表示,所以其长度为(len) = ((ptr)[1] << 24) | ((ptr)[2] << 16) | ((ptr)[3] << 8) | (ptr)[4])

