本文主要简要介绍一下JuiceFS,不错从本文开始又要开一个新坑了,计划后续还会出JuiceFS源码分析的文章。本文就打算先用JuiceFS的官方的资料来介绍一下JuiceFS,最后再说一下自己的一些想法。下面提到的核心特性、技术架构、应用场景均出自文末链接中的官方资料。
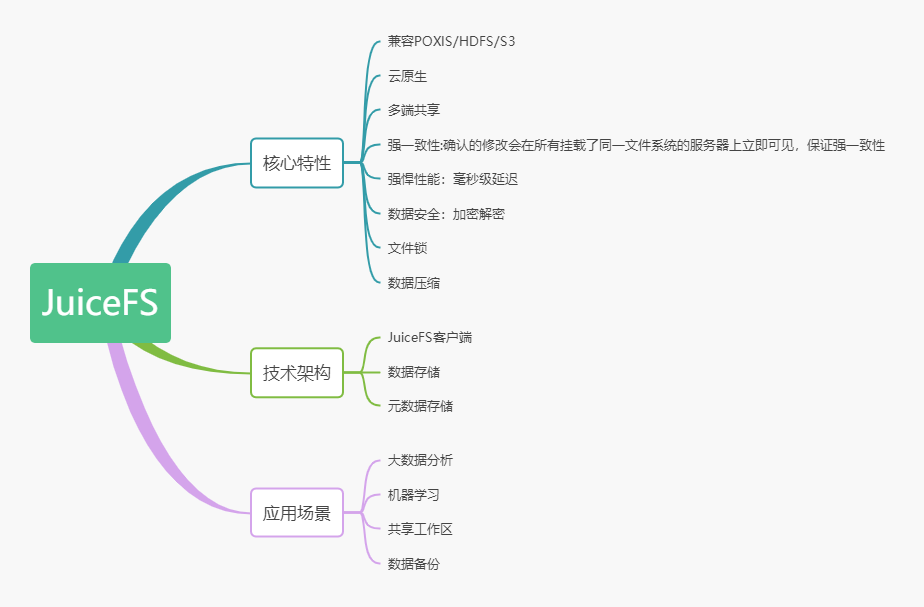
核心特性
- POSIX 兼容:像本地文件系统一样使用,无缝对接已有应用,无业务侵入性;
- HDFS 兼容:完整兼容 HDFS API,提供更强的元数据性能;
- S3 兼容:提供 S3 网关 实现 S3 协议兼容的访问接口;
- 云原生:通过 Kubernetes CSI Driver 可以很便捷地在 Kubernetes 中使用 JuiceFS;
- 多端共享:同一文件系统可在上千台服务器同时挂载,高性能并发读写,共享数据;
- 强一致性:确认的修改会在所有挂载了同一文件系统的服务器上立即可见,保证强一致性;
- 强悍性能:毫秒级的延迟,近乎无限的吞吐量(取决于对象存储规模),查看性能测试结果;
- 数据安全:支持传输中加密(encryption in transit)以及静态加密(encryption at rest),查看详情;
- 文件锁:支持 BSD 锁(flock)及 POSIX 锁(fcntl);
- 数据压缩:支持使用 LZ4 或 Zstandard 压缩数据,节省存储空间;
技术架构
JuiceFS 文件系统由三个部分组成:
- JuiceFS 客户端:协调对象存储和元数据存储引擎,以及 POSIX、Hadoop、Kubernetes、S3 Gateway 等文件系统接口的实现;
- 数据存储:存储数据本身,支持本地磁盘、对象存储;
- 元数据引擎:存储数据对应的元数据,支持 Redis、MySQL、TiKV 等多种引擎;

作为文件系统,JuiceFS 会分别处理数据及其对应的元数据,数据会被存储在对象存储中,元数据会被存储在元数据服务引擎中。
在数据存储方面,JuiceFS 支持几乎所有的公有云对象存储,同时也支持 OpenStack Swift、Ceph、MinIO 等私有化的对象存储。
在元数据存储方面,JuiceFS 采用多引擎设计,目前已支持 Redis、MySQL/MariaDB、TiKV 等作为元数据服务引擎,也将陆续实现更多元数据存储引擎。欢迎 提交 Issue 反馈你的需求!
在文件系统接口实现方面:
- 通过 FUSE,JuiceFS 文件系统能够以 POSIX 兼容的方式挂载到服务器,将海量云端存储直接当做本地存储来使用。
- 通过 Hadoop Java SDK,JuiceFS 文件系统能够直接替代 HDFS,为 Hadoop 提供低成本的海量存储。
- 通过 Kubernetes CSI driver,JuiceFS 文件系统能够直接为 Kubernetes 提供海量存储。
- 通过 S3 Gateway,使用 S3 作为存储层的应用可直接接入,同时可使用 AWS CLI、s3cmd、MinIO client 等工具访问 JuiceFS 文件系统。
应用场景
JuiceFS 广泛适用于各种数据存储和共享场景,本页汇总来自世界各地的 JuiceFS 应用案例,欢迎所有社区用户共同来维护这份案例列表。
数据备份、迁移与恢复
- 利用 JuiceFS 把 MySQL 备份验证性能提升 10 倍
- 跨云数据搬迁利器:Juicesync
- 下厨房基于 JuiceFS 的 MySQL 备份实践
- 如何用 JuiceFS 归档备份 Nginx 日志
大数据
- JuiceFS 如何帮助趣头条超大规模 HDFS 降负载
- 环球易购数据平台如何做到既提速又省钱?
- JuiceFS 在大搜车数据平台的实践
- 使用 AWS Cloudformation 在 Amazon EMR 中一分钟配置 JuiceFS
- 使用 JuiceFS 在云上优化 Kylin 4.0 的存储性能
- ClickHouse 存算分离架构探索
AI
数据共享
总结
上面三个方面的介绍可以总结如下图:
个人觉得JuiceFS的想法挺好的,官方提了很多的优点,个人比较喜欢的优点如下:
能抓到目标用户的痛点,尤其是其核心特性兼容POXIS、HDFS、S3这个特性。
在HDFS和对象存储广泛使用的今天,在很多公司都有广泛的应用。
如果只在大数据生态里面往往不容易看到 POSIX 的意义,因为 Hadoop 生态都是基于 HDFS 设计的,但是在今天我们的应用生态正在发生一些变化,尤其最近两年深度学习和机器学习的应用越来越普及,很多团队都在用 TensorFlow、PyTorch 这样的深度学习框架做模型训练。这些框架大部分是基于 POSIX 文件系统设计的,而这些数据集的规模往往又非常庞大,很多时候要用 Hadoop 的计算引擎做预处理。这就意味着我们需要把数据在 HDFS 中做预处理,把结果再搬到 POSIX 文件系统中做训练。如果有一个文件系统,同时兼容 POSIX、HDFS,可能还有其他的接口,能够支持你需要的所有应用生态,数据可以在其中被共享访问,Data Pipeline 可以简化很多。
架构设计的思考演进,不重复造轮子,把握能力边界,而不至于把整个项目搞得非常庞大
架构方面JuiceFS总共三个模块,想想GFS也不就是三个模块:master,client,chunkserver(datanode)。JuiceFS也类似,不过JuiceFS没有把重点放在重复造轮子,比如说去做数据节点的存储,而是直接使用现在非常普遍的对象存储。元数据也可以直接使用开源的Redis、SQL等(当然商业版元数据这块他们还是使用的自己研发的元数据存储引擎)。他们开源的JuiceFS等于是重点放在做client,解决用户实际使用现有的各种存储上存在的一些容易被我们忽略的痛点。
对于JuiceFS架构设计这块可以看看官方这篇文档:云上全托管 HDFS 技术解析,比较详细的介绍他们为什么会这样设计。
优点说了,也说说缺点:
- 目前开源JuiceFS还并没有经过充分的测试验证,可能还存在一些未知的bug
- 有的逻辑比较复杂的代码也没注释,导致理解困难
不过开源JuiceFS也还在继续完善中,可以看到官方也不断地加入新的功能,支持的元数据引擎也越来越多,而且社区也比较活跃,笔者在测试使用的时候发现了一个小bug,提issue当天就修复了该bug,响应速度很快[手动赞一个]。
最后再列一下JuiceFS目前支持的对象存储和元数据存储引擎。
| Name | Value |
|---|---|
| Amazon S3 | s3 |
| Google 云存储 | gs |
| Azure Blob 存储 | wasb |
| Backblaze B2 | b2 |
| IBM 云对象存储 | ibmcos |
| Scaleway | scw |
| DigitalOcean Spaces | space |
| Wasabi | wasabi |
| Storj DCS | s3 |
| Vultr 对象存储 | s3 |
| 阿里云 OSS | oss |
| 腾讯云 COS | cos |
| 华为云 OBS | obs |
| 百度云 BOS | bos |
| 金山云 KS3 | ks3 |
| 美团云 MMS | mss |
| 网易云 NOS | nos |
| 青云 QingStor | qingstor |
| 七牛云 Kodo | qiniu |
| 新浪云 SCS | scs |
| 天翼云 OOS | oos |
| 移动云 EOS | eos |
| 优刻得 US3 | ufile |
| Ceph RADOS | ceph |
| Ceph RGW | s3 |
| Swift | swift |
| MinIO | minio |
| WebDAV | webdav |
| HDFS | hdfs |
| Redis | redis |
| TiKV | tikv |
| 本地磁盘 | file |
JuiceFS 已经支持的元数据存储引擎:

