
在开始实际介绍管理ZFS数据集之前,我们需要确切地理解ZFS是如何存储数据的。所以,这篇文章将是理论性的,涵盖了一些你需要理解的概念:也就是默克尔树和写时复制。我将尝试将它在一个更容易理解的纬度来介绍它们,而不涉及到具体的C代码。
Merkle Trees(默克尔树)
默克尔树不过是加密哈希树,由拉尔夫·默克尔(Ralph Merkle)发明。为了理解一棵默克尔树,我们将从树的底部开始,并按照我们的方式往上爬。假设你有4个数据块,块0,块1,块2和块3。每个块都经过加密哈希处理,它们的哈希存储在一个节点或“哈希块”中。每个数据块与其散列块之间都有一对一的关系。让我们假设使用的哈希是SHA-256加密哈希算法。进一步假设我们的四个块散列如下:
- Block 0- 888b19a43b151683c87895f6211d9f8640f97bdc8ef32f03dbe057c8f5e56d32 (hash block 0-0)
- Block 1- 4fac6dbe26e823ed6edf999c63fab3507119cf3cbfb56036511aa62e258c35b4 (hash block 0-1)
- Block 2- 446e21f212ab200933c4c9a0802e1ff0c410bbd75fca10168746fc49883096db (hash block 1-0)
- Block 3- 0591b59c1bdd9acd2847a202ddd02c3f14f9b5a049a5707c3279c1e967745ed4 (hash block 1-1)
我们对每个区块进行加密哈希的原因是为了确保数据的完整性。如果区块故意改变,那么它的SHA-256哈希值也应该改变。如果块已损坏,则哈希不会改变。因此,我们可以用SHA-256算法对块进行加密哈希,并检查它是否与其父哈希块匹配。如果是匹配,那么我们就可以确定这个区块很大概率没有被破坏。但是,如果哈希不匹配,那么在相同的前提下,块很可能已损坏。
哈希树通常是二叉树(一个节点最多有2个子节点),尽管没有必要这样做。假设在我们的例子中,哈希树是一棵二叉树。在这种情况下,哈希块0-0和0-1将有一个共同的父节点,哈希块0。哈希块1-0和1-1将有一个共同的父节点,哈希块1(如下所示)。哈希块0是将哈希块0-0和哈希块0-1连接在一起的SHA-256哈希值。哈希块1也是类似的。因此,我们将得到以下输出:
- Hash block 0- 8a127ef29e3eb8079aca9aa5fc0649e60edcd0a609dd0285d1f8b7ad9e49c74d
- Hash block 1- 69f1a2768dd44d11700ef08c1e4ece72c3b56382f678e6f20a1fe0f8783b12cf
我们以类似的方式继续爬升Merkle树,直到我们到达超级哈希块、超级节点或者叫超级块。它是整个树的父节点,它只不过是其所有子节点连接起来的SHA-256散列。因此,对于我们例子中的超级块,是将哈希块0和1连接在一起,我们将得到以下输出:
- Uber block- 6b6fb7c2a8b73d24989e0f14ee9cf2706b4f72a24f240f4076f234fa361db084
*
这个超级块负责验证整个默克尔树的完整性。如果一个数据块改变了,所有的父哈希块也应该改变,包括超级块。如果在任何一点上,一个散列与它相应的子节点不匹配,则树中就存在不一致或数据损坏。
ZFS使用Merkle树来验证整个文件系统及其中存储的所有数据的完整性。当您对存储池进行数据清理时,ZFS将验证Merkle树中的每个SHA-256哈希,以确保没有损坏的数据。如果存储池中存在冗余,并且发现了损坏的数据块,那么ZFS将使用这些散列在池中的其他位置寻找相同位置的良好数据块。如果找到好的数据,它将使用该块修复损坏的那个数据,然后在Merkle树中重新验证SHA-256哈希。
默克尔树常被应用于数字签名,P2P网络,可信计算,区块链等领域,更多关于其介绍可以参考文章:Merkle Tree(默克尔树)解析
写时复制(COW, Copy-on-write)
写时复制又叫写前拷贝(copy -on-write, COW)是一种数据存储技术,在该技术中,你对将要修改的数据块做一个拷贝,而不是直接修改数据块。然后更新指针以查看新的块位置,而不是旧的块位置。您还可以释放旧块,因此,与修改原始块相比,您不会使用更多的磁盘空间。但是,您确实对底层数据进行了严重的分段。但是,数据存储的COW模型为我们的数据提供了以前不可能或很难实现的新特性。
COW最大的功能是对你的数据进行快照。因为我们在文件系统的其他地方复制了块,所以旧的块仍然存在,即使它已经被文件系统标记为空闲。
在下图中,当一个数据块被更新时,哈希树也必须被更新。以子块开始的所有散列及其所有父节点必须用新的散列更新。黄色块是数据的复本,在文件系统中其他地方,父散列节点被更新以指向新的块位置。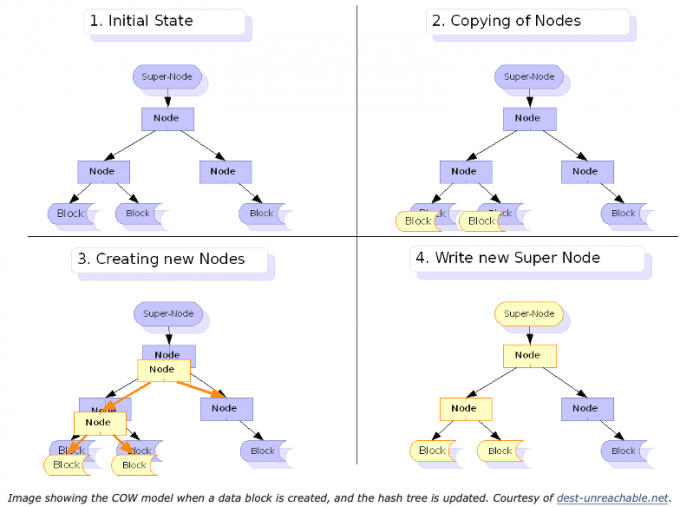
如前所述,COW会产生很多的碎片磁盘。这可能会对性能产生巨大影响。因此,需要做一些工作来提前分配块,以最小化碎片。有两种基本方法:使用b树预分配区段,或者使用slab方法,为复制标记磁盘的slab。ZFS使用slab方法,而Btrfs使用b树方法。
通常,文件系统以4KB大小的块写入数据。ZFS以128KB大小的块的形式写入数据。其次,slab分配器将分配一个slab,然后将这个slab分割成多个128 KB的块。第三,ZFS每5秒向磁盘同步一次数据。所有剩余数据将在30秒后刷到磁盘。这使得大量数据在slab中同时被刷新到磁盘。因此,这大大增加了相似数据在同一slab中的概率。因此,在实践中,即使COW正在碎片化文件系统,我们也可以做一些事情来极大地减少碎片。
不仅ZFS使用COW模型,Btrfs、NILFS、WAFL和新的Microsoft文件系统ReFS也使用COW模型。许多虚拟化技术使用COW来存储VM镜像,例如Qemu。COW文件系统是数据存储的未来。我们将在以后的帖子中更详细地讨论快照,以及COW模型是如何发挥作用的。
其他资料对ZFS COW的介绍
首先说下ZFS的copy on write 这个技术并不复杂,看下图比较清晰,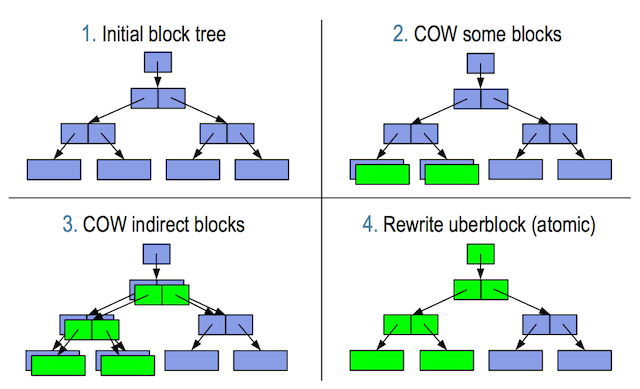
图-1: 可以看到uberblock实际上是Merkle Tree的root. 它记录了文件系统的所有状态,当检索一个数据块的时候, 会从uberblock这里一路往下查找metadata block同时比较checksum, 直到找到对应的数据块。
图-2: 当写一个新的block 时,没有performance的影响,当修改一个旧的block时,需要先copy一份, 实际上会带来一些performance的问题, 实际上所有的metadata和checksum都是需要复制新建。 但COW和Transaction技术一起,可以对数据的一致性得到比较好的保护。
图-3: 数据已经写入,上层的metadata和checksum的数据也已经修改好,但uberblock还没被更新,这个时候断电重新启动,数据不会丢失,我们仍然可用找到修改的数据, 然后将uberblock原子的更新。
图-4: uberblock是通过原子的方式,所有绿色的部分都已经更新。
COW 带来另一个好处是Snapshot,Replication非常方便, 如下图:
做snapshot只需要找上图中不同颜色的相关的数据指针即可!
再看Replication, 如下图:
这里Merkle Tree的每个父亲节点都有一个birth time的元数据,birth time代表着transaction group的ID.这时如果想要复制19-37之间的数据就非常的容易,找到所有birth time大于19的父亲节点再使用数据指针和checksum的数据,找到对应的数据块即可用。
参考资料
https://pthree.org/2012/12/14/zfs-administration-part-ix-copy-on-write/

